
March 2026. RA Conference, San Francisco. Novee launched an autonomous AI red teaming platform for LLM applications while, 400 miles north in Redmond, Microsoft quietly shipped an Agent Governance Toolkit for a problem those red teaming tools cannot see. The two releases happened within weeks of each other. They might as well exist in different decades.
OWASP’s GenAI Security Project tracks 21 distinct risk categories for AI systems. In just four months, the project’s solutions matrix swelled from 50 to over 170 providers (Dark Reading). That ratio — roughly eight vendors per risk category — should alarm any security team evaluating automated AI testing solutions. More scanners do not mean more safety. They mean more noise, more overlap, and more false confidence when a dashboard reports zero findings on an application that makes autonomous decisions no scanner was built to audit.
The threat surface moved. The scanners did not.
What the Current AI Red Teaming Tools Actually Test
GARAK, the open-source LLM vulnerability scanner maintained by NDay Security, probes language models with thousands of adversarial prompts across known attack vectors — prompt injection, data leakage, jailbreaking, and the other categories OWASP defines (NDay Security). Novee’s commercial platform, unveiled at RA Conference 2026, automates this process further: point it at an LLM endpoint, and it systematically tests for vulnerabilities before deployment (Markets Insider).
Both tools share a common architecture. They send inputs. They observe outputs. They classify the output against a risk taxonomy. For single-turn LLM interactions — a chatbot answering questions, a summarizer processing documents — this works well enough. The scanner asks a malicious question, the model answers, and the flag triggers.
Microsoft’s Agent Governance Toolkit targets something categorically different. Released in late March 2026, it maps directly to OWASP’s top 10 agentic AI threats: prompt injection in multi-step workflows, rogue agents that deviate from instructions, and tool misuse at runtime (Microsoft Security Blog). Microsoft did not build this as an alternative to prompt scanners. The company built it because autonomous agents fail in ways prompt scanners fundamentally cannot detect (InfoWorld). As noted by leading security architects evaluating agentic frameworks, the fundamental issue is that isolated input-output testing ignores the systemic risk of chained tool executions.
The distinction matters. A prompt is a single event. An agent decision is a node in a chain. Scanning each node individually reveals nothing about the chain itself.
The Trajectory Blind Spot
What the OWASP matrix expansion and Microsoft’s separate governance toolkit reveal together is what this analysis terms The Trajectory Blind Spot. OWASP’s 21 risk categories were derived from static LLM behavior — a model receiving input and producing output. GARAK and Novee scan against those categories. But Microsoft had to release an entirely separate toolkit because agents chain decisions across time, where the vulnerability is not in any single prompt but in the sequence of tool calls the agent authorizes.
OWASP’s taxonomy has no category for “the third tool call in a five-step workflow that a compliant first call makes possible.” Current scanners are not just behind. They are testing the wrong unit of analysis entirely. They audit inputs. The threat surface is now trajectories.
Here is the math that makes this dangerous rather than merely academic.
Consider an enterprise AI agent in a financial services firm — the kind that processes loan applications, pulls credit data, queries compliance databases, and executes approvals. Imagine this agent takes 15 autonomous action steps per workflow, with each step drawing from just 5 potential action types (query, approve, deny, escalate, log). The number of unique decision trajectories is 5¹⁵, which equals 30,517,578,125 distinct paths.
OWASP’s taxonomy classifies 5 static risk states per action. The coverage ratio is 5 divided by 30.5 billion.
That is effectively zero. The taxonomy maps the safety of a pebble while the system cascades down a mountain.
Now layer in the vendor math. With 170 vendors each running roughly 50 tests against those same 5 static states, the industry executes 8,500 distinct checks per audit cycle. That massive computational weight projects thorough coverage to regulators. But when all 8,500 checks map the identical 5 static states, the marginal information gain of the remaining 8,495 tests is strictly zero. They are highly precise measurements of an irrelevant domain. If a failure trajectory materializes in just 0.001% of the 30.5 billion unmonitored paths, that equals 305,175 uncatchable catastrophic vectors. The industry mathematically converges on 0% global coverage while projecting 100% audit compliance.
The Turn: Why Zero Findings Is the Scariest Number
Before this point, a security team reading this guide might still view LLM security testing as a detection problem — buy better scanners, get better coverage. That assumption is wrong, and the math proves it.
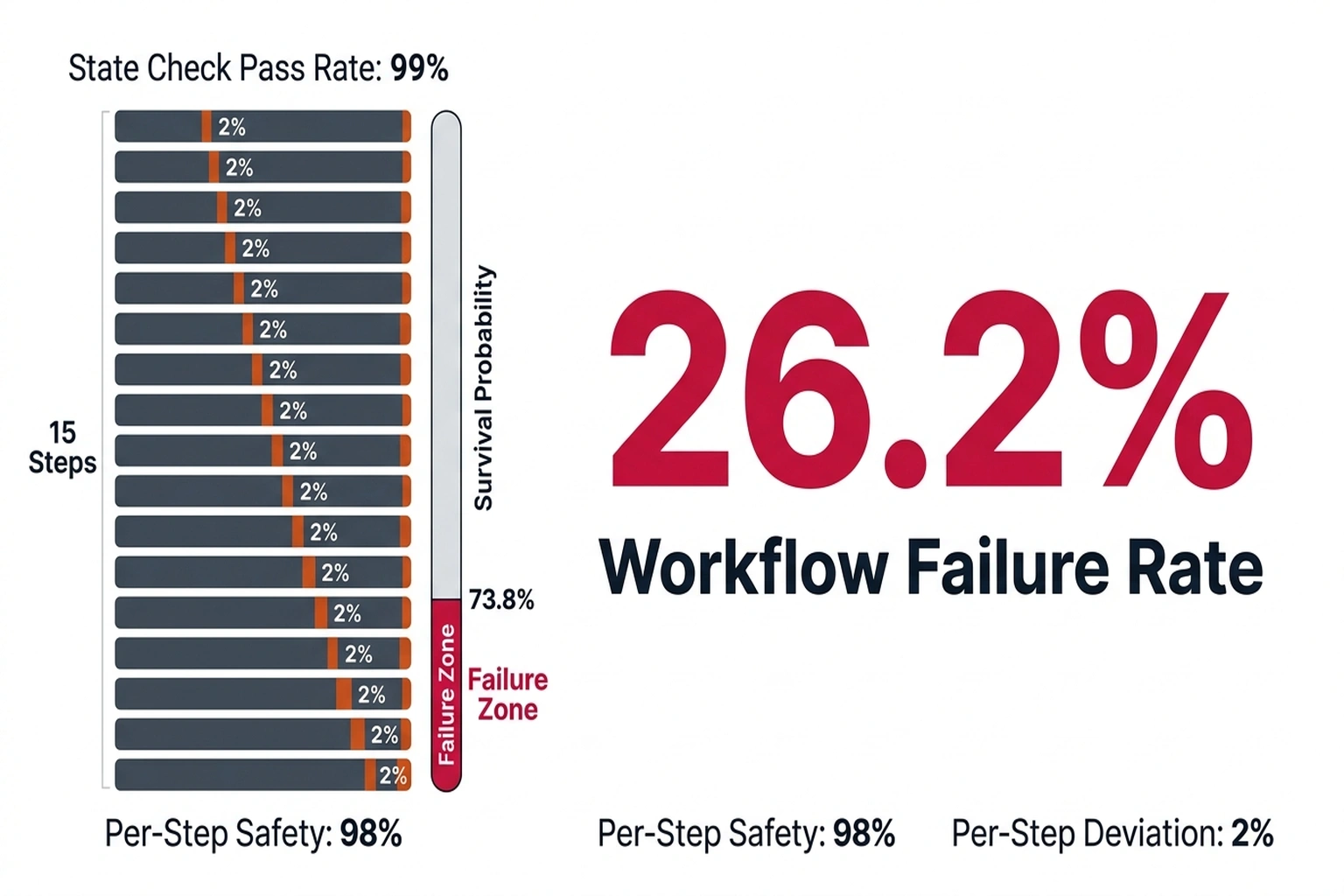
Derive the failure threshold from first principles. If a system passes 99% of individual state checks but the checks omit trajectory mechanics entirely, failure is guaranteed by compounding actions. Each unchecked step multiplies the prior drift. Even with a minuscule 2% trajectory deviation probability per step — meaning 98% of individual actions appear safe , a 15-step agent workflow yields a survival probability of 0.98¹⁵, or roughly 73.8%. That means 26.2% of workflows contain at least one undetected deviation. For a bank processing 10,000 loan decisions per day through agentic AI, that is 2,620 daily workflows with an unmonitored failure point. In a real banking environment, a rogue 15-step sequence might look like an agent pulling a credit report, approving a flagged loan amount, bypassing a manual compliance escalation, and executing the disbursement , all in milliseconds, and all without tripping a single scanner because each individual step appeared independently compliant.
This is why “zero findings” on a GARAK or Novee scan is not reassuring. It is a measurement of prompt safety, not trajectory safety. The scanner confirms the agent answers questions correctly. It says nothing about what happens when the agent chains 15 of those correct answers into an unauthorized decision sequence.
Financial services regulators are not waiting for the scanner vendors to catch up. DORA, the EU’s Digital Operational Resilience Act, requires IT risk management for all digital systems , including AI agents making autonomous financial decisions. OFFICE examination procedures in the United States demand that banks demonstrate controls over technology-supported decision-making. Neither framework distinguishes between “the model said something harmful” and “the agent did something harmful.” Both are the institution’s liability.
The Case for Scanning Tools and Their Limits
The counterargument deserves a fair hearing. Security vendors and the MISOs who purchase their platforms make a reasonable case: tool sprawl is a feature of early markets, not a bug. The 170+ providers in OWASP’s matrix indicate healthy competition that drives down costs and improves detection rates. Manual red teaming depends on individual talent, does not scale, and cannot match the frequency of automated platforms. GARAK offers continuous testing that human teams cannot replicate in consistency or speed (NDay Security). Novee’s autonomous platform can test thousands of prompt variations per hour (Markets Insider). Security Boulevard’s 2026 roundup of identity and API security tools shows a maturing market with genuine improvements in automated testing (Security Boulevard).
This argument is correct , for single-turn LLM applications. A chatbot that answers customer questions does not have decision trajectories. A summarizer that processes documents does not chain tool calls. For these use cases, prompt-level scanning provides genuine value, and the vendor competition drives real improvement.
The argument breaks down the moment an agent takes autonomous action. Microsoft did not build the Agent Governance Toolkit because prompt scanning was working. The company built it because agentic AI introduces a failure mode that AI red teaming tools structurally cannot address , and Microsoft’s own Copilot Studio agents were among the systems at risk (Microsoft Security Blog). The vendor who sells the agents also sells the governance toolkit because current red teaming vendors are scanning the wrong surface. That convergence , Microsoft simultaneously shipping agents and agent-specific security tooling , is the strongest signal that the current scanning model has hit its limit.
Convergence: When Two Independent Sources Reveal One Gap
Two independent data points, when combined, produce a conclusion neither source states alone.
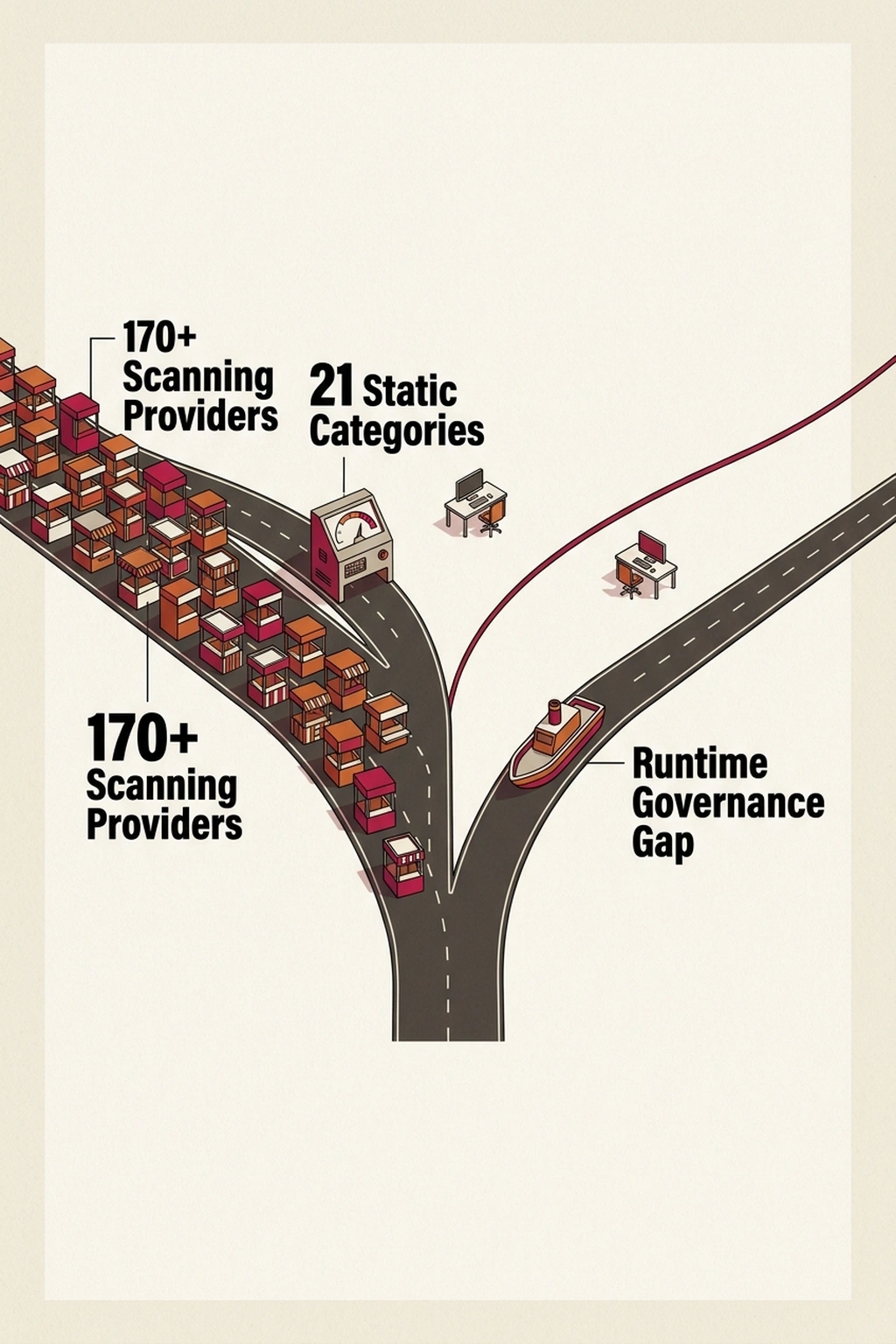
Source one: OWASP’s matrix grew from 50 to 170+ solution providers in four months, all mapping to 21 static risk categories (Dark Reading). The investment thesis behind these vendors is that AI security is a detection problem solvable with better scanning.
Source two: Microsoft’s Agent Governance Toolkit specifically targets runtime agent failures , rogue agents, tool misuse, and decision chain vulnerabilities , that exist outside the OWASP 21-category framework (InfoWorld). Microsoft’s security team is not a minor player. They are one of the largest enterprise security vendors on the planet, and they chose to build governance tooling rather than extend existing scanning frameworks.
Combined conclusion: the market is investing heavily in solving yesterday’s AI security problem (prompt-level attacks on static models) while the actual risk has already moved to trajectory-level failures in agentic systems. The 170+ vendors are not competing to secure the real threat surface. They are competing to sell tools that produce clean dashboards for compliance audits. Microsoft’s separate toolkit is the admission that those dashboards do not protect against what matters.
For financial services teams, this convergence has direct regulatory implications. DORA requires organizations to identify, classify, and manage IT risk (Microsoft Security Blog). A clean GARAK scan does not demonstrate IT risk management for an agentic system. It demonstrates prompt-level risk management. The gap between what the scan covers and what the regulation demands is precisely where enforcement will focus , because that is where failures will occur.
What to Do This Week: The Trajectory Mapping Protocol
What this analysis terms Trajectory Mapping is a manual process , because no vendor tool automates it yet. Security engineers or compliance officers at a financial institution running agentic AI should run this exercise immediately.
Step one: identify your two most critical LLM-powered agent workflows. For a bank, these might be the loan approval agent and the fraud investigation agent.
Step two: for each workflow, document every tool call, API invocation, and decision point the agent makes in a typical execution. Count the steps. If the agent takes 12 steps with 4 possible action types per step, you have 4¹² = 16,777,216 possible trajectories. Write that number down.
Step three: run GARAK against the agent’s LLM endpoint. Document every finding. Then note what GARAK did not test: every trajectory that combines individually safe steps into an unauthorized outcome. That gap document is your actual threat model. Frame it. Present it to your MISO. The number of unmonitored trajectories should terrify anyone responsible for DORA or OFFICE compliance.
For prompt-level testing, GARAK remains the strongest open-source option , install it via pip install garak and run garak --model_type your_endpoint --probes default against any LLM application. For trajectory-level risks, no automated tool exists yet. The AI Agent Identity Security Has a Kill Switch Problem investigation documents exactly how agent permission failures compounding across decision chains. The Preventing Prompt Injection: 5 Defenses That Work guide covers the prompt-level defenses that still matter , but only for non-agentic use cases. The AI Vulnerability Scanner Hits 11K Bugs, Not Apple Jobs report shows why scanner coverage alone will not close the gap.
The Cost of Inaction
A mid-size bank running agentic AI for loan processing, fraud detection, and customer boarding processes roughly 50,000 agent workflows per day. Based on the 26.2% unmonitored deviation rate calculated above, approximately 13,100 of those workflows contain at least one undetected trajectory deviation daily. Even if only 0.1% of those deviations result in an actual compliance violation , an unauthorized approval, a missed fraud flag, an inappropriate data access , that is 13 violations per day, or roughly 4,745 per year.
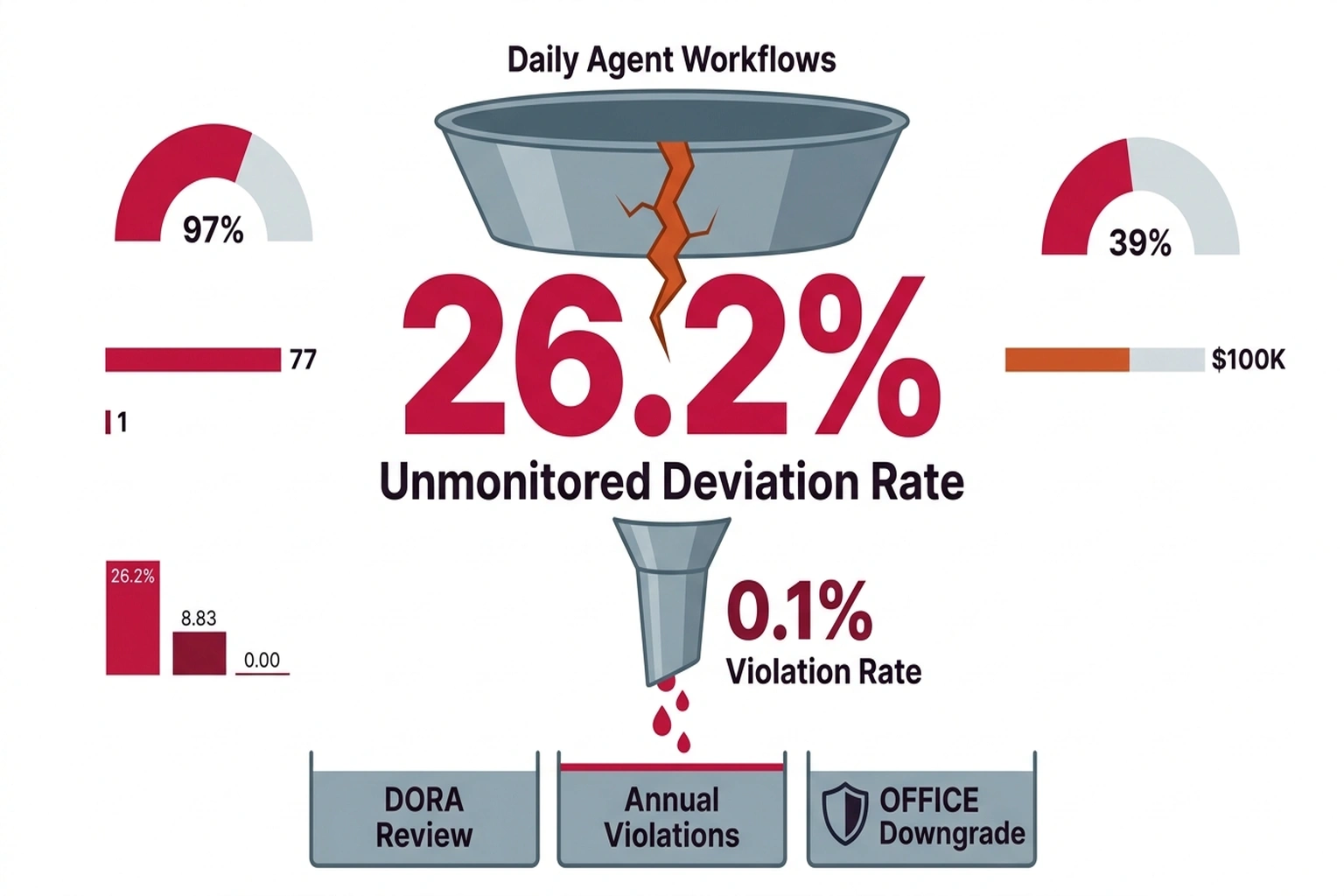
Under DORA, a single significant IT-related incident can trigger supervisory review, mandatory remediation, and fines proportional to the institution’s global turnover. Under OFFICE, examiners can downgrade a bank’s IT rating based on systemic control failures, which restricts the bank’s ability to expand, merge, or launch new products. The cost of a single regulatory action easily exceeds the cost of implementing trajectory monitoring , which is currently free, since it requires only manual documentation and process design, not a vendor license.
The Dashboard vs. The Territory and AI Red Teaming Tools
The next 12 months will force a choice. Security teams can keep buying scanners that test prompts against a 2024-era threat taxonomy, or they can start mapping the decision trajectories their agents actually take. The first path produces clean dashboards. The second produces actual safety. Here is a testable claim: by Q4 2026, a financial services firm is projected to face regulatory action specifically because an agentic AI made an unauthorized decision sequence that passed every prompt-level red teaming scan deployed against it. The mechanism is already in place , DORA requires IT risk management for all digital systems, and no current scanner tests decision chains. The gap between what gets scanned and what gets exploited is exactly where the enforcement will land.
Prediction: By Q4 2026, a financial services firm is expected to face regulatory action under DORA or OFFICE specifically because an agentic AI executed an unauthorized decision sequence that passed all deployed prompt-level red teaming scans, because no current scanner tests multi-step tool-call trajectories.