
Part 3 of 5 in the Benchmark Reality Checks series.
Alibaba’s Qwen 3.5 scores 87.8% on MMLU-Pro, edging past GPT-5.2’s 87.4%. On the knowledge benchmark that headlines use, a model activating 17 billion of its 397 billion parameters per query just outscored the American frontier model most teams measure against.
On LMArena, where users rank models through blind head-to-head comparisons, Qwen 3.5-Max-Preview sits in 15th place globally, as noted by Geeky Gadgets, behind Anthropic and Google in the top three, behind models it outscores on MMLU-Pro. Top Chinese model on the leaderboard. Fifteenth in the world.
That 14-position gap between the Qwen 3.5 benchmark headline and user reality isn’t measurement error. It raises a question the AI industry has been sidestepping: what exactly are benchmarks measuring, if a model can win on the test and lose in the room?
What 4.3% Activation Actually Buys
Sparse mixture-of-experts architecture isn’t new. Qwen 3.5 pairs it with linear attention via Gated Delta Networks, a hybrid design that keeps 380 billion parameters dormant, roughly 47 for every person alive on Earth, while routing each query through just 17 billion active weights. Ninety-five percent of the model never fires on any given query.
Alibaba’s broader family covers the full inference spectrum, four dense variants from 0.8B to 9B parameters, plus a hosted Plus version with a million-token context window. Running the Qwen 3.5 9B locally on what one reviewer calls “a few hundred dollars of hardware” drives marginal query cost toward zero.
Twelve months ago, single-benchmark parity required frontier-scale compute. Qwen 3.5 demonstrates that sparse architectures can achieve this at a fraction of the cost, but parity on one Qwen 3.5 benchmark out of forty published evaluations is not parity, and the other thirty-nine tell a different story.
What the Benchmark Table Actually Says
Pull up Alibaba’s release documentation and count. Across 40 language benchmarks published alongside the model, Qwen 3.5-397B-A17B leads GPT-5.2 on fifteen, knowledge retrieval (MMLU-Pro, SuperGPQA), multilingual performance (NOVA-63, PolyMATH), and several agent tasks (BFCL-V4, VITA-Bench). Fifteen wins from a model activating 4.3% of its total parameters is a genuine architectural achievement.
Even on MMLU-Pro, the headline metric, the picture is narrower than it appears. Per 17 billion of its 397 billion parameters87.8% on MMLU-ProAlibaba’s published benchmark tables, Qwen 3.5’s 87.8 trails both Claude 4.5 Opus at 89.5 and Gemini-3 Pro at 89.8. It outscores GPT-5.2 by 0.4 points, but GPT-5.2 is the fourth-place model on that same leaderboard. Efficiency parity against fourth place tells a different story than efficiency parity against the leader.
Now filter for the five hardest reasoning benchmarks. LiveCodeBench, both HMMT competition rounds, IMOAnswerBench, and AIME26. GPT-5.2 leads on all five, Per 87.8% on MMLU-Pro same release benchmarks. Margins range from 4.1 points on LiveCodeBench to 7.3 on HMMT November. AIME26 shows a 5.4-point gap, IMOAnswerBench the same. Knowledge parity vanishes the moment the questions require reasoning.
Two calculations from Alibaba’s own data that neither the blog post nor community benchmark aggregations surfaced:
Average deficit across five reasoning benchmarks: (4.1 + 4.6 + 7.3 + 5.4 + 5.4) / 5 = 5.4 points.
Win rate by category: 15 of 40 benchmarks overall (37.5%). On the five hardest reasoning benchmarks: 0 of 5 (0%). On knowledge and multilingual benchmarks: 15 of 35 remaining (43%). (per “benchmark leaders in general reasoning do not always)
Structural, not random: Qwen 3.5 wins every category that rewards recall and loses every category that rewards reasoning. And here is the turn the headline obscures: it’s not that benchmarks are broken, it’s that the wrong benchmark got the headline. MMLU-Pro measures whether a model knows things. LMArena measures whether a model does things the way a user intended. Qwen 3.5 aced the exam that tests memory. Users graded it on the exam that tests judgment.
AI Productivity’s editorial analysis argues that “benchmark leaders in general reasoning do not always hold that lead on specialized domain tasks.” That critique is right about the symptom but wrong about the cure, it implies switching to the correct domain-specific benchmark resolves the evaluation problem, when LMArena’s data shows the problem runs deeper. Batch evaluation on curated test suites, domain-specific or otherwise, fails to surface what LMArena captures: whether the model handles ambiguous instructions with the nuance real users expect.
That structural split, 37.5% overall win rate, 0% on reasoning, quantifies the “Benchmark-Vibes Gap”: the measurable distance between what a model scores on curated knowledge tests and how it performs on interactive, instruction-heavy tasks. MMLU-Pro measures recall. LMArena measures compliance with intent. Based on the calculations in this analysis, the 0-for-5 reasoning record suggests the 15th-place ranking before a single user votes, per Alibaba’s own evaluation tables.
Reasoning isn’t the only dimension. On IFEval, the benchmark most directly measuring instruction adherence. Qwen 3.5 scores 92.6 against GPT-5.2’s 94.8, a 2.2-point deficit, per Alibaba’s own evaluation tables. On paper, trivial. In practice, IFEval measures whether the model does precisely what a user asked, and every fraction of a point maps to instructions followed or ignored.
Why Fifteenth and Not Fifth
As of March 20, Qwen 3.5-Max-Preview leads every Chinese competitor on LMArena. Anthropic holds the top two positions, Google takes third, and the fourteen models ranked above Qwen 3.5 include several that score lower on the benchmarks it wins. In blind comparisons, users preferred those lower-scoring models anyway.
Fifteenth is not a failure. It’s a mismatch, and understanding what LMArena tests explains why.
LMArena pits models against each other on real user prompts: draft this email but make it sound firm, not aggressive. Refactor this function but keep the API contract. Explain this concept but assume I already know X. These tasks have no single correct answer.
They require the model to infer unstated constraints, calibrate tone, and make judgment calls about what the user meant versus what they literally typed. A model optimized for knowledge retrieval, for having the right answer, can still fail these comparisons by delivering that answer in the wrong format, at the wrong level of detail, or with the wrong assumptions about what the user already knows.
This is exactly what the IFEVal deficit predicts. A 2.2-point gap on instruction following may sound small, but IFEval is a ceiling metric, most frontier models cluster above 90%. At that altitude, 2.2 points means systematically missing edge cases in formatting, constraint satisfaction, and implicit instruction parsing. When a user asks for “a brief summary” and gets four paragraphs, the knowledge is correct. The vibes are wrong. Multiply that mismatch across thousands of blind comparisons and the result is a 14-position LMArena gap.
One bright spot: fifth globally in mathematics, trailing only dedicated reasoning variants from Anthropic and OpenAI. Math problems have clear right answers. Instruction following has taste. Qwen 3.5 excels where correctness is binary and struggles where quality is subjective, a pattern consistent with what the Benchmark-Vibes Gap framework predicts.
Alibaba described the model as undergoing final tuning ahead of release within the next two weeks. RLHF tuning could narrow the IFEval deficit. But even a best-case five-position climb lands Qwen 3.5 at 10th, still meaningfully below models it outperforms on knowledge benchmarks. Targeted evaluation against representative tasks remains essential, but only if those tests include instruction-following metrics. As research on context degradation has demonstrated, architectural constraints persist through fine-tuning.
One caveat: LMArena rankings here reflect a preview release, and the platform’s crowdsourced preference methodology introduces its own biases, potentially favoring models tuned for English conversational fluency over multilingual capability.
Benchmarks captured the 87.8%. Users captured the 15th. But neither number answers the question procurement teams actually face: how do you convert that gap into a decision rule before you’ve already committed?
A Model Selection Formula Worth Running
Sorting by use case, the benchmark data converges:
| Task Type | Qwen 3.5-397B | GPT-5.2 | Gap |
|---|---|---|---|
| Knowledge recall (MMLU-Pro) | 87.8 | 87.4 | +0.4 |
| Instruction following (IFEval) | 92.6 | 94.8 | −2.2 |
| Code generation (LiveCodeBench) | 83.6 | 87.7 | −4.1 |
| Math reasoning (AIME26) | 91.3 | 96.7 | −5.4 |
| User preference (LMArena) | 15th | Top 3 (per source) | −12+ ranks |
| Verdict | Non-interactive, batch workloads | User-facing, instruction-dependent | Match to use case |
For teams evaluating models, one formula captures the Benchmark-Vibes Gap as a number:
vibes_gap = headline_benchmark_rank - lmarena_rank
if vibes_gap > 5: trigger mandatory hands-on evaluation
Qwen 3.5’s MMLU-Pro rank of roughly 3rd minus its LMArena rank of 15th yields a gap of 12. GPT-5.2, ranking 4th on MMLU-Pro and in the top three on LMArena, gaps at roughly 1. Twelve versus one. Based on the calculations in this analysis, that formula diagnoses what the headline obscures.
For ML engineers: weight IFEval and LiveCodeBench 2-3x higher than MMLU-Pro for any user-facing deployment. For engineering managers: add LMArena position to procurement criteria, any gap above five warrants hands-on testing before commitment. For CFOs: as hidden reasoning costs can inflate output bills by 5x, the cheaper inference model may carry higher downstream costs from instruction-following failures. For research teams: Qwen 3.5’s multilingual scores, including a field-leading 59.1 on NOVA-63, per Alibaba’s benchmarks, make it a strong candidate for non-English knowledge tasks where instruction adherence matters less than factual accuracy.
Model the cost of ignoring the gap. Each IFEval deficit point correlates with additional prompt engineering overhead, workarounds for instructions the model misinterprets or refuses. At a conservative 2 hours per engineer per week compensating, a five-person team absorbs meaningful hidden cost:
$80/hour × 2 hours/week × 52 weeks × 5 engineers = $41,600/year in prompt workarounds.
A model that looks cheaper on the benchmark can cost significantly more in the workflow. That ratio, not the MMLU-Pro score, not the parameter count, not the activation percentage, is the number that belongs in procurement decks.
Critics of this framing point out that LMArena’s crowdsourced preference methodology may itself be a poor proxy for real-world deployment value, a model that ranks 15th on English conversational preference could still be the correct choice for the majority of enterprise workloads, which involve structured data extraction, document processing, and multilingual pipelines where Qwen 3.5 leads the field. The strongest version of this counterargument holds that the Benchmark-Vibes Gap is only a gap if your vibes, your users’ preferences, are the thing you’re optimizing for, and for many high-value production systems, they simply aren’t.
Verdict: When to Choose Qwen 3.5 and When to Walk Away
Choose Qwen 3.5 for workloads where the model processes data, not conversations, batch classification, embedding generation, multilingual knowledge extraction. The smaller dense variants nearly match models 13x their size on key benchmarks, and for local inference, the cost advantage is decisive.
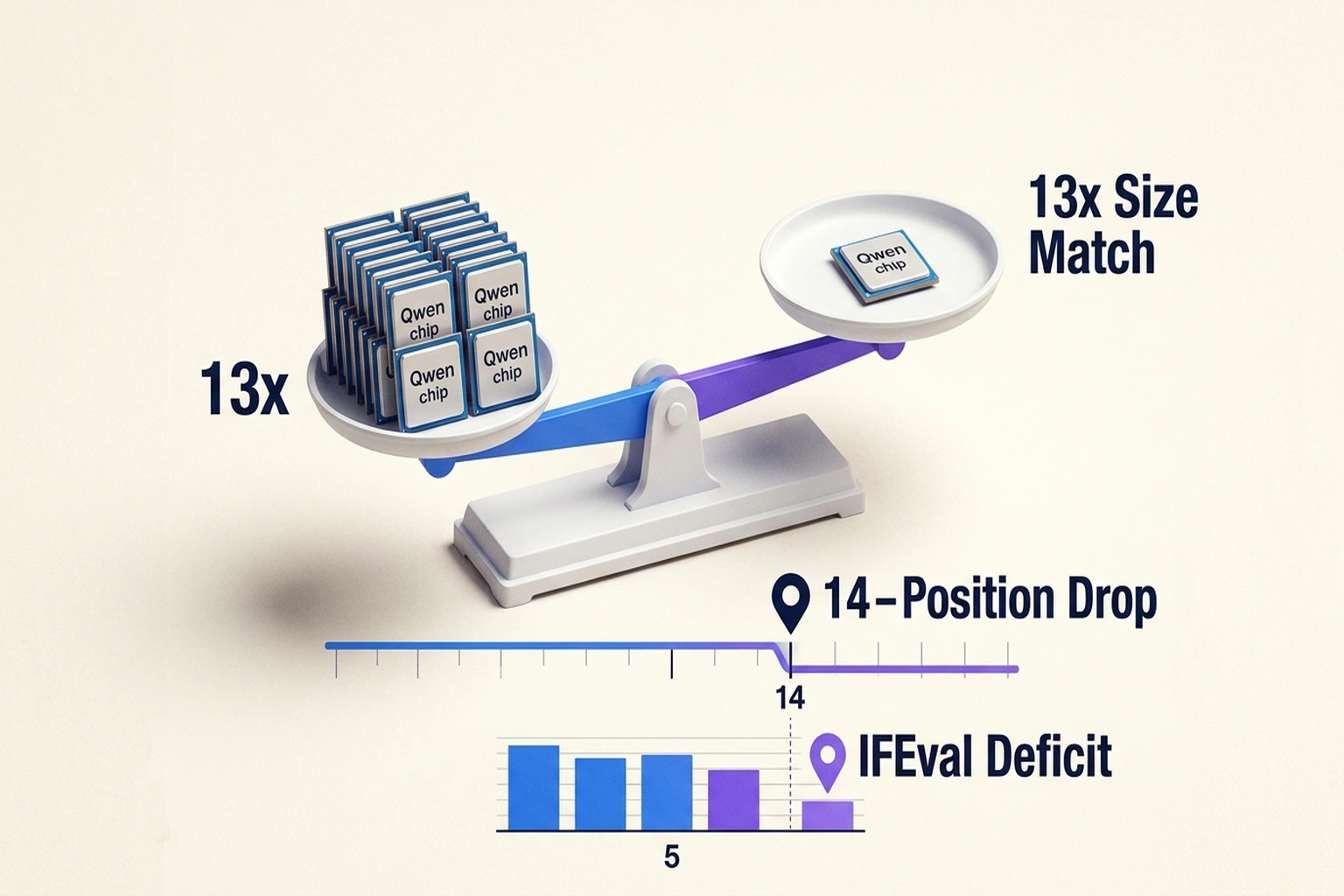
Walk away for user-facing chat, coding assistants, agentic workflows, or any deployment where instruction adherence determines user satisfaction. The IFEval deficit, the coding gap, and the 14-position LMArena drop all converge. If your vibes gap exceeds five, invest in hands-on evaluation before procurement, not after.
One limitation worth stating directly: this analysis weights Alibaba’s self-reported benchmark scores against LMArena’s crowdsourced preference data, two measurement systems with different methodologies, incentive structures, and failure modes. Independent reproduction of the benchmark results using standardized, third-party evaluation harnesses would strengthen the comparison; until then, the 12-position gap provides directional reliability but lacks precision.
Alibaba built the most parameter-efficient frontier model in the world, and users ranked it fifteenth. That outcome is already a template: sparse MoE delivers recall parity at a fraction of the compute cost, but recall parity and deployment readiness are different products. The lab that ships a sparse MoE architecture with IFEval scores above 96 and LMArena parity with the top three will have solved both halves of the problem simultaneously, and based on the trajectory of Qwen’s instruction-tuning iterations from Qwen 2 through Qwen 3.5, this analysis identifies Alibaba as the most likely candidate to do it by Q2 2027. When that model ships, the procurement calculus in this article becomes obsolete. Until then, the vibes gap formula is the most honest evaluation tool available.
What to Read Next
- TurboQuant’s 6x Compression Creates More GPU Demand
- GPT-5.4 Mini vs Nano: Small Model Costs Hide a 33-Point Cliff
- Helios Turns a $400 GPU Into a Real-Time AI Video Studio
References
- Qwen3.5: Towards Native Multimodal Agents , Primary benchmark data, architecture details, and full evaluation tables
- Geeky Gadgets: Qwen 3.5 Benchmark Scores , Major outlet coverage of model performance and rankings
- Preview of Alibaba’s strongest AI model tops Chinese peers, lags US rivals , LMArena ranking data and Alibaba development timeline
- Aggregated Benchmark Analysis Compares Qwen 3.5 to Qwen 3 , Independent community analysis of benchmark methodology
- Qwen 3.5 Small Models Review: Benchmarks and Real Testing , Small model variant performance and cost analysis
- Context Rot Drops Claude to 78% Accuracy at 1M Tokens , Architectural limitation persistence through fine-tuning
- AI Reasoning Costs Hit 5x as Hidden Tokens Surge , Hidden cost structures in model selection
“`