
Part 4 of 6 in the AI Agent Crisis series.
Lukasz Grochal’s February 2026 framework benchmark measured what every agent developer argues about: output consistency, token efficiency, and cost per run, comparing LangGraph vs CrewAI alongside Microsoft Agent Framework. Developer forums picked winners. MIT research analyzing 300+ AI implementations suggests they’re all losing — only 5% of enterprise AI solutions make it from pilot to production.
Comparing LangGraph vs CrewAI on token costs and prototype speed produces useful data. What follows covers all three contenders with production benchmarks — then explains why the factor that’s 6x more predictive of production success has nothing to do with framework selection.
The State Machine That Saves $6,570 a Year
LangGraph models agent systems as directed graphs where nodes are Python functions or LLM calls and edges define state transitions. Developers code every call explicitly, map every retry path in the graph, and inspect the full agent state at any checkpoint.
Production benchmarks on a 3-agent pipeline processing 10,000 daily GPT-4o requests tell the cost story. LangGraph runs $32/day; CrewAI runs $50/day. The former carries zero automatic system prompt overhead — each token sent to the model is developer-controlled. The latter injects approximately 150 tokens of role scaffolding per agent per call, a 56% per-request overhead that the architecture bakes in.
Annualized, that $18/day gap compounds to $6,570(https://markaicode.com/vs/langgraph-vs-crewai-multi-agent-production/). For a small business running agent workloads on constrained API budgets, that’s the difference between shipping and a budget conversation nobody wants to have.
Latency follows the same pattern. On parallel 3-agent tasks, the same benchmarks measured 4.2 seconds for the graph-based tool versus 7.8 seconds for the role-based system in hierarchical mode. The hierarchy adds an LLM-driven manager call per delegation — three extra inference passes before any agent starts working.
Twelve months ago, agent frameworks were experimental libraries with unstable APIs. LangGraph is now the only benchmarked framework with a 1.0 GA release, offering the stability enterprise procurement demands. A 3-agent pipeline can require 150+ lines of boilerplate graph definition — thinking in state machines rather than role descriptions demands a mental model shift that not every team completes before the project deadline arrives.
The 30-Line Prototype and What It Costs in Production
CrewAI makes the opposite bet: developer velocity over production control. A working 3-agent crew ships in roughly 30 lines of code. Roles, goals, and backstories are defined in natural language that non-engineers can read and modify without touching graph syntax.
“Most teams get stuck between ‘working demo’ and ‘production system,'” wrote João Moura, CrewAI’s CEO, reflecting on 2 billion workflow executions powered by the framework in its first year. Production surfaces the tradeoffs that prototyping hides. Debugging means parsing stdout logs — no programmatic access to mid-run agent state. Developers on the enterprise platform have reported documented deployment delays with tasks stuck in pending status, and agents occasionally “hallucinate delegation,” routing work to the wrong crew member with no structured trace of why.
Moura’s own blog title captures the honest tension: “Your First AI Agent Should Do One Thing Badly.” Ship fast. Fix in production. At enterprise scale, that philosophy has delivered billions of executions. It has not delivered a production survival rate that justifies the confidence.
Consistency Over Community
Microsoft Agent Framework, which absorbed AutoGen in late 2025, posted the highest output consistency in Grochal’s analysis — standard deviation of just 0.10 versus AutoGen’s 0.45. On cost, it ran roughly $60 per 1,000 runs against CrewAI’s $220 — nearly four times cheaper at scale, with the most predictable output of any tested option. For teams where per-run cost determines profitability, those numbers rewrite the spreadsheet.
One asterisk matters: MS Agent Framework remained in beta at benchmarking time, with GA reportedly expected around March 2026. Betting production workloads on a pre-GA API takes a specific appetite for breaking changes. Worth watching. Skip it for anything customer-facing until the API contract stabilizes.
Where the Comparison Breaks Down
Every framework debate thread gets the question wrong.
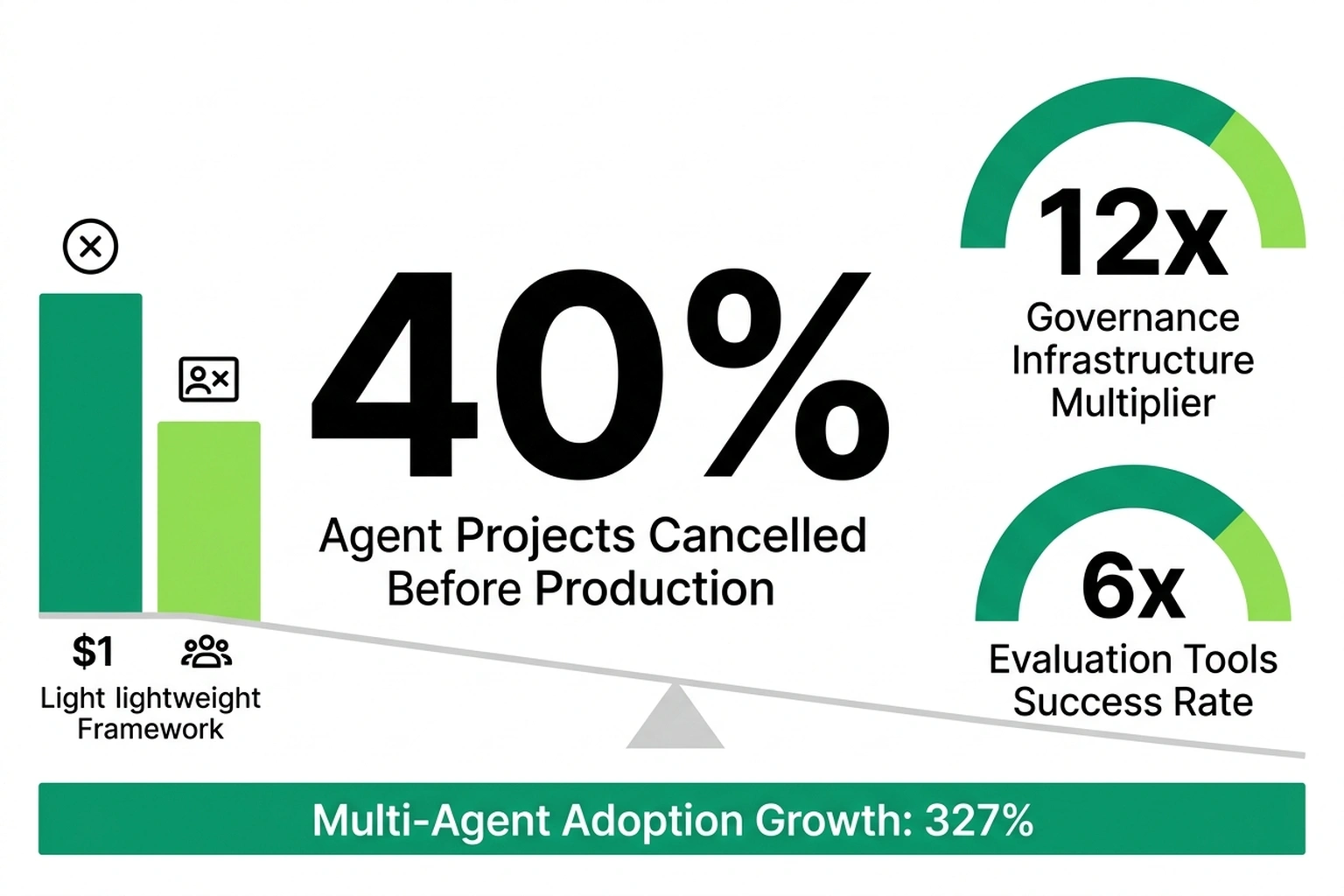
Databricks’ State of AI Agents report found that companies using evaluation tools get nearly 6x more AI projects into production. Companies deploying governance infrastructure see a 12x multiplier. Meanwhile, multi-agent system adoption grew 327% in under four months among Databricks customers — and 40% of agentic AI projects still face cancellation before reaching production.
What Databricks’ production data and TechTrends’ failure analysis independently reveal — two studies measuring different populations through different methods, separate from the token cost and consistency benchmarks that also rely on different models and workloads — is the Framework Selection Fallacy — Engineering teams spend weeks evaluating state graphs versus role definitions while neglecting the infrastructure that actually predicts survival. Framework choice is a marginal variable. Evaluation tooling dominates.
Neither source calculated the cost of that misallocation. At 10,000 daily requests, the annual token cost gap between these frameworks is $6,570. Production evaluation platforms cost $25-40/month — roughly $300-480 per year. Teams prioritize token cost savings 13.7x more heavily than they invest in tooling that’s 6x more predictive of shipping(https://markaicode.com/vs/langgraph-vs-crewai-multi-agent-production/)(https://airbyte.com/agentic-data/best-ai-agent-frameworks-2026). A Cleanlab survey of 1,837 engineering leaders, cited in the same analysis, found that 70% of regulated enterprises rebuild at least part of their agent stack every quarter(https://airbyte.com/agentic-data/best-ai-agent-frameworks-2026). Evaluation infrastructure persists through rebuilds; framework code doesn’t.
Underlying data has limits — Databricks’ self-reported customer data and MIT’s observational research are not controlled experiments on framework-specific survival. Independent verification would require data no current study provides. Even so, the directional signal across both datasets is strong enough to act on.
A Real Hearing for the Other Side
Moura’s velocity-first position has empirical weight. Choosing a framework readable by non-engineers carries legitimate organizational value — especially in small businesses where the AI team is one person who also handles DevOps, monitoring, and the on-call rotation.
Grochal’s data adds nuance too. Not every agent workflow needs complex branching, conditional logic, or cycles. For teams processing under 500 requests per day where token cost isn’t the binding constraint, the role-based system’s gentler learning curve works. Ship the demo, land the contract, optimize later — that’s a viable strategy when the alternative is never shipping at all.
Reasonable people hold both positions. Framework choice matters at the margins, especially at scale. Agonizing over it before building evaluation infrastructure breaks the strategy. One is a $6,570/year adjustment. The other is a 6x multiplier on whether the project lives or dies.
Which Framework for Which Problem
| Criterion | LangGraph | CrewAI | MS Agent Framework |
|---|---|---|---|
| Token cost (10K req/day) | ~$32/day | ~$50/day | ~$60/1K runs |
| Parallel latency (3 agents) | 4.2s | 7.8s (hierarchical) | Sequential only |
| Time to prototype | Days (learning curve) | Under 1 hour | Beta (API unstable) |
| Debugging | Full state inspection | Stdout logs only | Sequential tracing |
| Enterprise users | Klarna, Cisco, Vizient | IBM, PwC, Gelato | Pre-GA |
| Verdict | Production pipelines >1K req/day | Prototypes and role-based tasks | Wait for GA |
Data from MarkAICode and AI-Buzz benchmarks; enterprise deployments from Airbyte framework guide. All cited in preceding sections.

For solo developers and small teams, CrewAI’s prototype velocity decides — shipping a demo this week outweighs saving $18/day on tokens. For engineering leads managing agent portfolios, Databricks’ multiplier leaves no ambiguity: evaluation tooling first, framework second. For budget owners, a team skipping evaluation faces the standard 5% production survival rate on a project investment that compounds every sprint.
Three things to build before the framework debate eats another planning cycle:
Deploy evaluation tooling before writing a single agent node. Evaluation tools deliver 6x more projects to production; governance delivers 12x. Platforms like LangSmith, Braintrust, and Humanloop start at $25-40/month. Chasing $6,570/year in token cost savings while deferring $480/year in evaluation investment fixes the wrong line item. For teams already running agent observability stacks, evaluation is the natural next layer.
Prototype in CrewAI, ship in LangGraph. “Validate topology in CrewAI, then rewrite the production path in LangGraph once design stabilizes” — this hybrid approach captures the role-based tool’s velocity without inheriting its debugging gaps. Evaluation infrastructure transfers between frameworks; the tests and metrics stay constant when the orchestration layer swaps out.
Budget for the rebuild. At a 70% quarterly stack replacement rate(https://airbyte.com/agentic-data/best-ai-agent-frameworks-2026), the framework selected today remains provisional. Isolate business logic from framework glue code. When enterprise analysis found 80% of AI projects failing at $7.2M each, survivors treated their framework as disposable scaffolding, not a permanent foundation.
Forty percent of agentic projects will fail before shipping. Of the survivors, MIT’s 5% pilot-to-production baseline applies with full force(https://airbyte.com/agentic-data/best-ai-agent-frameworks-2026). By Q4 2026, expect at least two major framework vendors to bundle evaluation pipelines as standard features — collapsing framework selection and production monitoring into a single purchase decision. Until then, the 5% survival rate will keep drawing blame on framework choice. The data says otherwise.
What to Read Next
- JPMorgan’s AI Mandate Hides a 39-Point Perception Gap
- AI Coding Tools Cost $6,750/yr in Hidden Rework — 5 Ranked by True Price
- Shadow AI Costs $21K Per App: The 3:1 Ratio Nobody Tracks
References
- New AI Agent Benchmark: LangGraph vs CrewAI for Production — Grochal’s consistency benchmarks, MS Agent Framework cost and variance data, LangGraph GA status
- Best AI Agent Frameworks for 2026 — MIT pilot-to-production research (5%), enterprise deployment data, Cleanlab survey on quarterly stack rebuilds, evaluation platform pricing
- LangGraph vs CrewAI: Multi-Agent Performance and Cost in Production 2026 — Token cost benchmarks ($32 vs $50/day), latency measurements (4.2s vs 7.8s), system prompt overhead analysis, hybrid prototype-to-production recommendation
- State of AI Agents — Evaluation tool production multiplier (6x), governance multiplier (12x), multi-agent adoption growth (327%)
- Why 40% of Agentic Projects Fail: Lessons from the 2026 Leaders — Agentic project failure rates attributed to Gartner and industry analysts
- Lessons From 2 Billion Agentic Workflows — João Moura on CrewAI enterprise scale, 2 billion execution volume, architecture compounding effects
- Your First AI Agent Should Do One Thing Badly — João Moura on CrewAI’s velocity-first philosophy for agent development
- LangGraph Official Documentation — High-Level Concepts — LangGraph’s directed graph architecture, node/edge state transition model