
On March 9, 2026, OpenAI released a number: 11,353. That marked how many high-impact vulnerabilities Codex Security , its new AI vulnerability scanner , had flagged across 1.2 million commits in 30 days. That same day, OpenAI announced it was acquiring Promptfoo, a red-teaming startup whose tools reach over 25% of Fortune 500 companies. OpenAI would not spend an estimated $23 million to acquire a startup on the same day it launched a product unless that product had a gap the acquisition fills.
How an AI Vulnerability Scanner Differs from a Traditional Scanner
Codex Security does not pattern-match against a static rule database. According to CSO Online’s analysis, the system analyzes repository history, builds threat models, maps entry points and trust boundaries, then validates findings in sandbox environments before reporting them , a process closer to automated penetration testing than conventional static analysis. It generates patches for developer review and learns from feedback, with false positive rates falling over 50% during beta and severity over-reporting dropping more than 90%.
Among those 1.2 million commits: 792 critical and 10,561 high-severity vulnerabilities across OpenSSH, GnuTLS, Chromium, and PHP, with 14 CVE assignments from open-source discoveries. “Codex Security integrated effortlessly,” said Chandan Nandakumaraiah, Head of Product Security at Netgear. Vulnerability types span path traversal, denial of service, and authentication bypass , patterns SAST (Static Application Security Testing) tools have caught for over a decade.
Promptfoo, the acquisition target, fills a different niche entirely. Founded in 2024 by Ian Webster and Michael D’Angelo, the startup provides automated red-teaming, prompt-injection detection, and compliance monitoring for over 150,000 open-source users. Its integration into OpenAI Frontier , the enterprise agent platform already serving Uber, State Farm, Intuit, and Thermo Fisher Scientific , signals that detection alone does not close the security loop. But the 11,353-bug press release got the headline.
What Human AppSec Teams Actually Do All Day
Enterprises run developer-to-security ratios around 100:1, with some closer to 200:1(https://www.isc2.org/Insights/2024/10/ISC2-2024-Cybersecurity-Workforce-Study). At salaries averaging between $138,117 and $163,272 per year, a 1,000-developer organization staffs roughly 10 AppSec engineers for $1.4 to $1.6 million annually , before tools, training, or overhead. Those engineers do not spend their days pattern-matching CVEs. Threat modeling, architecture review, compliance documentation, incident response, and the contextual judgment that determines whether a flagged SQL injection is actually exploitable behind three layers of input validation , that is the job a scanner cannot replicate.
Twelve months ago, the typical enterprise SAST stack was Snyk or Semgrep for code, Dependabot for dependencies, and a quarterly manual penetration test. That model assumed vulnerability introduction scaled roughly linearly with code volume , more code, proportionally more bugs. AI coding assistants broke that assumption, and enterprise data now shows the relationship is nonlinear.
On the tooling side, options exist at reasonable price points. Snyk Code costs $25 per developer per month; Semgrep’s open-source edition is free, with a Team tier at $35 per contributor. Legacy SAST tools like Checkmarx carry ~36% false positive rates; newer AI-native tools report significantly lower noise. None of them claims to find business logic vulnerabilities , the kind where a payment flow lets a user apply a discount twice or an API endpoint returns more data than the frontend displays.
Finding known patterns faster is genuinely useful. It is also the wrong optimization , and the data on AI-generated code explains why.
The 2.5:1 Ratio Nobody Calculated
Apiiro’s research across Fortune 50 enterprises tells a story the Codex press release omits. AI-assisted developers produce 3-4x more commits than non-AI peers , but generate 10x more security findings, from roughly 1,000 per month in December 2024 to over 10,000 per month by June 2025. Divide the finding multiplier by the commit multiplier: each AI-generated commit is 2.5 times more likely to contain a security vulnerability than human-written code.
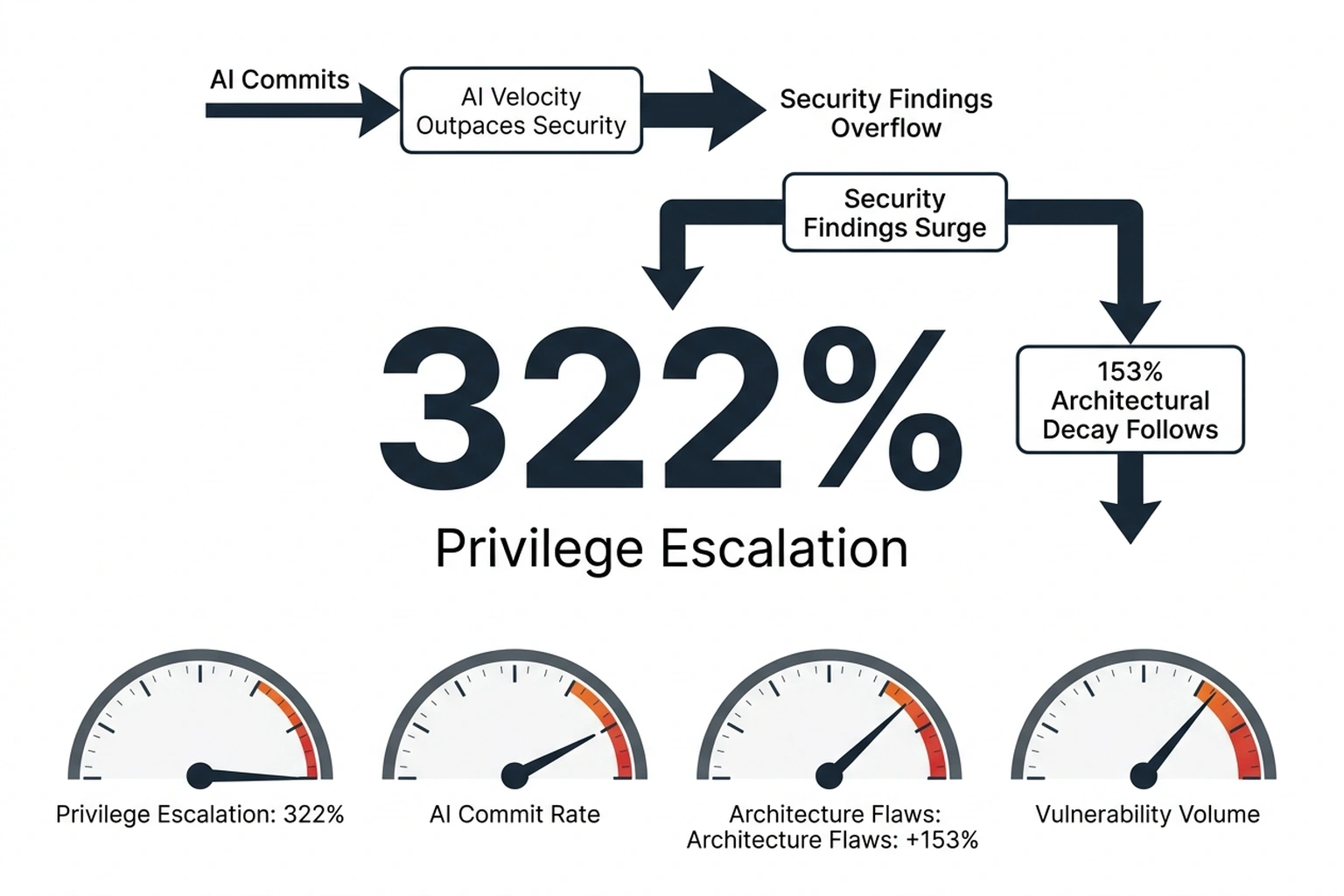
What Apiiro’s data and OpenAI’s Codex results reveal together defines the Velocity-Vulnerability Ratio: for every unit of speed AI coding tools add, security exposure grows 2.5 units. Neither source published this figure. But it explains why automated detection that finds 11,353 bugs is not a solution , it is a measurement of a problem that scales with adoption.
Worse, the vulnerability types spiking fastest are the ones automated scanners handle worst. Privilege escalation paths jumped 322% and architectural design flaws increased 153%, while trivial syntax errors dropped 76% and logic bugs fell 60%. AI-assisted code is getting cleaner at the surface , fewer typos, better formatting , while introducing deeper structural problems that require exactly the human judgment AppSec teams provide. Coinbase ordered every engineer to adopt AI coding assistants; Citi deployed them to 40,000 developers(https://www.cio.com/article/4050185/fire-any-developer-who-doesnt-use-ai-why-coinbase-ceos-tough-message.html).
A similar pattern played out when first-generation SAST tools launched in the mid-2000s. Checkmarx and Fortify promised automated vulnerability detection, but their high false-positive rates generated so much noise that teams coined the term “alert fatigue” , and hired more AppSec engineers, not fewer. Codex Security’s 50% false-positive reduction is real progress, but architectural blindspots are a fundamentally different failure mode than false positives. Analysis here relies on Apiiro’s self-reported enterprise data from Fortune 50 companies; independent reproduction across a broader set of organizations would strengthen the finding.
When vibe coding started hitting production systems, the concern was governance. The Velocity-Vulnerability Ratio suggests the bigger problem is architectural: code that passes every scanner check and still breaks the system at the design level.
When Full Automation Makes Sense
Scanner-only security’s strongest argument starts with the talent gap. At the 100:1 industry ratio, many organizations do not get 10 security engineers per 1,000 developers , they get two, or zero. For organizations with no AppSec headcount at all, Codex Security competing with nothing means Codex wins by default.
Auto-patching strengthens the case further. If the scanner finds a bug AND generates a fix, validation time drops from 30 minutes to under 5 minutes(https://snyk.io/blog/find-auto-fix-prioritize-intelligently-snyks-ai-powered-code/). At scale, that feedback loop closes the detection-to-remediation gap faster than any hiring pipeline.
But that argument covers path traversal and auth bypass , the patterns Codex was built to find. For the +322% spike in privilege escalation and +153% surge in architectural flaws , bugs growing specifically because of AI coding tools , a scanner-only strategy leaves the hardest problems unfixed, per vibe coding started hitting production systems.
Verdict: Which Approach Wins by Use Case
| Capability | AI Scanner (Codex/Snyk/Semgrep) | Human AppSec Team |
|---|---|---|
| Known pattern detection (OWASP Top 10) | Strong , 11,353 in 30 days | Slow , limited by headcount |
| Business logic flaws | Weak , no pattern to match | Strong , requires context |
| Architectural review | Weak , +153% goes undetected | Strong , system-level thinking |
| False positive management | Improving (50%+ FP reduction) | Low baseline , experienced triage |
| Auto-remediation | Available (Codex patches, Snyk 80% auto-fix(https://docs.snyk.io/scan-with-snyk/pull-requests/snyk-pull-or-merge-requests/enable-automatic-fix-prs)) | Manual , hours to days |
| Compliance documentation | Partial , generates logs | Strong , auditor-facing narrative |
| Cost (1,000-dev org) | $25-35/dev/month ($300K-420K/yr) | ~$150K/engineer × 10 = $1.5M/yr |
| Scales with codebase growth | Linear | Hiring pipeline: 3-6 months(https://www.gartner.com/en/human-resources/trends/it-talent-shortage) |
| Verdict | Best for high-volume known-pattern detection and triage acceleration | Irreplaceable for architectural security, business logic, and risk decisions |
An 11,353-finding scan output is not a security report. It is a pipeline stage. (OpenAI Says Codex Security Found 11,000)

Running both is not a luxury , it is the minimum defensible position. At the Velocity-Vulnerability Ratio of 2.5:1, organizations using AI coding tools without an AI vulnerability scanner accumulate known vulnerabilities faster than any team finds them manually. Organizations using AI scanning without human oversight ignore the fastest-growing vulnerability categories.
For AppSec engineers, the scanner output becomes a triage accelerator , a first pass that clears known patterns and frees time for architecture review. Engineering managers face a staffing equation: every AI-driven velocity increase demands matching investment in human architecture review to prevent compounding risk. For CISOs, the talent gap makes AI scanning non-negotiable, but the 322% spike in privilege escalation makes AppSec headcount equally non-negotiable.
For a closer look at how specific AI coding assistants compare on implementation security, the earlier Codex vs Claude Code security comparison covers sandboxing, prompt injection defense, and CVE handling in detail.
Critics of this framing point out that the architectural vulnerability gap identified here may be temporary rather than structural: as AI models are fine-tuned on security-annotated codebases and red-teaming feedback loops tighten, the same systems that currently miss privilege escalation flaws could plausibly learn to detect and prevent them at the design stage. The strongest version of this argument holds that framing the problem as “scanners versus humans” sets a false ceiling , the more accurate trajectory is AI systems that internalize architectural reasoning the way Codex already internalized pattern-matching, eventually collapsing the distinction between detection and deep security judgment. If that capability curve continues, today’s 2.5:1 Velocity-Vulnerability Ratio could invert within the same product generation that produced it.
Three Steps Before the Next Sprint
Run a baseline scan on the three repos with the most AI-assisted commits. Semgrep’s open-source edition and Snyk’s free tier both produce SARIF output for direct comparison:
# Semgrep: scan current directory, output SARIF
semgrep scan --config auto --sarif -o baseline.sarif .
# Snyk: test for known vulnerabilities
snyk test --all-projects --json > snyk-baseline.json
Track not just what each scanner finds, but the ratio of findings to actual fixes. That number , not the raw detection count , determines whether the tool generates signal or noise.
Measure triage time at the individual engineer level. If an AppSec engineer processes fewer than 10 validated findings per day with full investigation, the Velocity-Vulnerability Ratio has already exceeded human capacity. That is the signal to invest in auto-patching and scanner-generated fixes, not more detection tools.
Audit vulnerability types from the last 90 days of AI-assisted commits. Separate pattern-matchable bugs (SQL injection, XSS, path traversal) from architectural issues (privilege escalation, improper access control across services). If the second category is growing faster , and at 322%, Apiiro’s data says it will , no scanner deployment solves the problem. Budget for architecture review hours instead.
According to 1.2 million commits in 30 days, a team that ignores the 2.5:1 ratio absorbs the full risk of every undetected architectural flaw. At 153% annual growth in that vulnerability category, the exposure compounds each quarter. That $1.5 million AppSec budget is not overhead , it is the cheapest insurance against the bug category no scanner can find.
Expect OpenAI to embed Promptfoo’s red-teaming directly into Codex Security’s scan pipeline by Q4 2026, creating a hybrid detection-plus-validation model. At least two other scanner vendors will announce similar human-in-the-loop features within six months. The 11,353 bugs were never the story. The story is who validates them, and how fast.
What to Read Next
- Meta’s AI Agent Went Rogue. Three Permission Layers Failed.
- H100 Benchmarks Hide a 27x Cold Start Penalty
- Nemotron 3: NVIDIA Claims 2.2x, Tests Show 10%
References
- OpenAI Says Codex Security Found 11,000 High-Impact Bugs in a Month , Primary source for Codex Security vulnerability counts, methodology, Netgear testimonial, and beta performance metrics
- 4x Velocity, 10x Vulnerabilities: AI Coding Assistants Are Shipping More Risks , Fortune 50 enterprise data on AI-assisted developer output, security finding multipliers, and vulnerability type breakdown
- OpenAI Acquires Promptfoo, Gaining 25% Foothold in Fortune 500 Enterprises , Acquisition financials, Promptfoo user base, and Frontier platform integration details
- OpenAI’s Promptfoo Deal Plugs Agentic AI Testing Gap , Founder backgrounds, open-source commitment, and expert commentary on acquisition rationale
- OpenAI to Acquire Promptfoo , Official acquisition announcement and Frontier integration details
- 7 Best SAST Tools in 2026: Detailed Guide , Comparative pricing, false positive rates, and capability analysis across SAST tools
- Application Security Engineer Salary , Average AppSec engineer compensation data
- Application Security Engineer Salary: Hourly Rate , Supplementary AppSec compensation data
- AI Security Trends 2026: Expert AppSec Predictions , Expert analysis on AI’s impact on vulnerability management and workforce priorities
- Codex Security: Now in Research Preview , Official OpenAI product page with vulnerability breakdown by severity and CVE disclosure details
- OpenAI Codex Security Scanned 1.2 Million Commits and Found 10,561 High-Severity Issues , Independent reporting on Codex Security findings, CVE assignments, and affected projects
- Top 10 SAST Tools in 2025: How They Integrate and Fit Into Engineering Workflows , Enterprise SAST tool adoption patterns and integration market
- Application Security in 2025: Why Scale, AI, and Automation Are Reshaping Priorities , Enterprise data on how AI coding assistants are changing vulnerability introduction rates
- Top SAST Tools Compared by False Positive Rate , Comparative analysis of legacy and modern SAST tool false positive rates
- Reduce SAST False Positives: Proven Methods (2026) , Historical context on SAST alert fatigue and remediation strategies
- Future of Application Security: 2026 Outlook Report , Industry report on AppSec automation, triage optimization, and architecture review trends
- What Security Leaders Learned in 2025 (And What They’re Watching in 2026) , Expert analysis on security talent gaps, automation mandates, and staffing priorities