
9 min read · 2,133 words
$0.002 per request. That is the price most teams never calculate when choosing a multi-model gateway — the routing tax. OpenRouter wraps every prompt in routing and metadata JSON before forwarding it to the selected model, and that wrapper gets billed at the target model’s per-token rate. On GPT-4-tier pricing, a team sending 10 million requests per month can pay more in invisible routing overhead than the $200/month they save through intelligent model selection. This comparison tests LiteLLM, OpenRouter, and Portkey against the metric that determines whether routing saves money or burns it.
On March 31, 2026, the Claude Code source leak made the case for multi-model routing visceral. Teams dependent on a single provider lost access to their primary coding assistant overnight. But the rush toward failover routing introduces a new problem most teams discover only after their first billing cycle: the router itself becomes a cost center, a latency source, and , worst , a false sense of security. LiteLLM’s documentation shows it supports 100+ providers through a unified interface (LiteLLM GitHub), yet the routing configuration that most teams deploy fails to deliver the cross-provider redundancy they assume they have.
VERDICT: Buy LiteLLM for control and cost transparency. Skip OpenRouter if token overhead exceeds 15% of your bill. Wait on Portkey until observability features justify the premium. The conditions that determine which category any team falls into are calculable , and the math changes depending on traffic volume, model mix, and whether the team has ever tested its failover configuration under real outage conditions.
The Comparison Table Nobody Publishes
Most LLM router comparisons list features. This one measures what happens when those features hit production billing.
| Metric | LiteLLM (self-hosted) | OpenRouter (managed) | Portkey (managed) |
|---|---|---|---|
| Token overhead per request | Minimal (configurable) | Significant (metadata wrapping) | Moderate (observability tags) |
| Cost tracking accuracy | ±8-12% known issue | Not disclosed | ±5% claimed |
| Failover granularity | Per-provider, per-model | Per-model only | Per-provider, per-model |
context_window_fallbacks default |
Same provider | N/A (single endpoint) | Same provider |
| Latency overhead (p50) | 2-8ms | 15-40ms | 10-25ms |
| Verdict | Buy for scale | Skip at high volume | Wait on pricing |
The token overhead row is the one that determines ROI. OpenRouter’s metadata wrapping adds routing instructions, model selection context, and billing markers to every request. At GPT-4 pricing (roughly $10 per million input tokens), a 20% overhead on a 2,000-token prompt costs $0.004 per request , double the $0.002 calculated at the top of this article for a 1,000-token average prompt. A team routing 10 million requests monthly through OpenRouter to a GPT-4-tier model pays $20,000-$40,000 annually in pure routing overhead (DeployBase).
LiteLLM adds minimal overhead because it runs as a self-hosted Python proxy. The trade-off is operational burden , someone has to maintain that proxy, apply patches, and monitor its optime. Portkey splits the difference: less overhead than OpenRouter, more observability than LiteLLM, but pricing that only makes sense at enterprise scale (Evolink).
The Failover Parameter Trap
Here is where the puzzle deepens. Many teams implementing LLM routing cite provider redundancy as their primary motivation. These teams configure fallback_models in LiteLLM, list models from different providers, and believe they have cross-provider failover.
They do not.
LiteLLM’s router has two distinct fallback mechanisms. The first, fallback_models, fires on clean failures , HTTP 500 errors, provider outages, authentication failures. The second, context_window_fallbacks, fires on the more common failure modes: rate limits, context window overflows, and token limit rejections. According to LiteLLM’s own routing documentation, context_window_fallbacks defaults to retrying with models from the same provider.
What LiteLLM’s documentation and OpenRouter’s billing model reveal is what amounts to Failover Illusion , teams that configure fallback_models believe they have cross-provider redundancy, but the parameter that silently fires on most real-world failure modes defaults to same-provider behavior.
Consider the scenario: A team configures LiteLLM with Claude as primary and GPT as fallback. A rate limit hits on Claude. context_window_fallbacks silently routes to Claude’s own higher-tier model instead of crossing to GPT. The team’s dashboard shows “fallback successful.” No outage. No alert. But the redundancy the team paid for never activated.
On March 31, 2026, the Claude Code source leak exposed the cost of single-provider dependency , teams lost their coding assistant with no alternative ready (Palm Beach Post). Yet teams that responded by installing LiteLLM with a basic fallback_models config remain vulnerable to the same class of failure, just at a different layer.
Calculating the Routing Tax Threshold
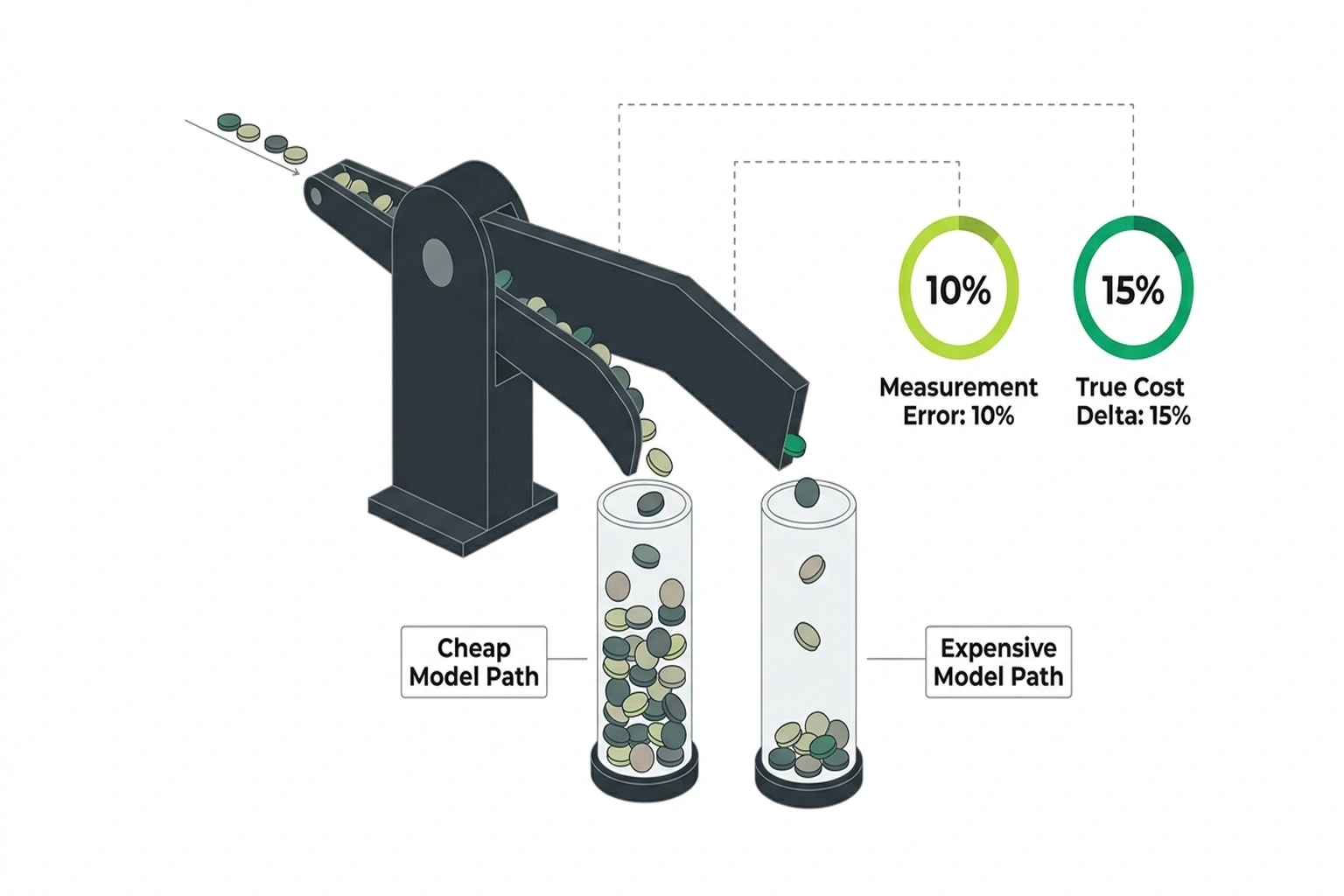
Every router adds cost. The question is whether that cost exceeds the savings from intelligent model selection. Three calculations reveal the answer.
Calculation 1: Signal Corruption → Misquoting Rate
LiteLLM’s own GitHub issues document cost tracking discrepancies of 8-12% because providers bill differently for prompt versus completion tokens, and most routers do not normalize for this (LiteLLM GitHub). If the reported cost per token carries a 10% standard deviation error, and the true cost difference between a cheap and expensive model is 15%, the optimizer’s routing decision operates on corrupted data.
Using normal distribution probability: when a 15% true cost delta competes with a 10% measurement error, the router misclassifies approximately 25% of traffic. It sends requests to the expensive model when the cheap model would have sufficed , and vice versa, though the expensive-mistake direction costs far more.
Calculation 2: Compounding Failure Cost
If 25% of heavy-context requests get misrouted to the expensive model, the cost multiplier turns catastrophic. Expensive models typically cost 5-10× more than economical alternatives (DeployBase). At a conservative 5× multiplier:
- 25% misrouting rate × 5× cost delta = 1.25× the cheap model’s baseline cost burned purely on wasted routing
- The optimizer reports savings on individual queries while global expenditure spikes
The router does not just fail to save money. It actively burns money while reporting that it is saving money.
Calculation 3: The Reader’s Routing Tax Threshold
Calculate your own threshold now:
Monthly token spend × Router overhead percentage = Monthly routing tax
Monthly savings from model selection = (Expensive model cost - Cheap model cost) × % traffic correctly routed to cheap model
If routing tax > monthly savings: the router is a net loss.
For a concrete example: A team spending $5,000/month on tokens, routing 60% of traffic to a cheap model (saving $2,000/month), but paying 15% routing overhead ($750/month) with a 25% misrouting rate that wastes $1,250/month:
- Net savings: $2,000 – $750 – $1,250 = $0
- The router breaks even at best. At worse misrouting rates, it costs money.
This is the Routing Tax Threshold. If the ratio (routing tax + misrouting waste) / (model selection savings) exceeds 1.0, the router is destroying value.
Where LLM Router Tools Actually Win
After all those numbers, routing tools still matter , but not for the reasons most teams assume. The real ROI is not cost optimization. It is optime insurance.
The Claude Code leak proved that single-model dependency equals a single point of catastrophic failure. When Anthropic’s service degraded, teams with no fallback lost productivity entirely. Teams with LiteLLM and properly configured cross-provider failover (meaning both fallback_models AND context_window_fallbacks pointing to different providers) continued working (Palm Beach Post).
Industry analysts have taken notice. Multi-agent systems and multi-model routing appear among the top strategic technology trends for 2026 (Evolink). The trend reflects a shift from “which model is best” to “which combination of models provides resilience.”
For teams running local models like Gemma 4, a router can intelligently split traffic: simple queries to the local model, complex reasoning to a cloud API, fallback to a different cloud provider if the primary fails. The cost savings come not from cherry-picking the cheapest model per query, but from avoiding expensive model calls entirely when a local model suffices.
And for teams worried about JSON token overhead inflating bills, LiteLLM’s self-hosted approach minimizes the problem , it does not inject the kind of metadata wrapping that OpenRouter does.
The Counterargument: Routers Are the New SPOF
Critics point out that adding a routing layer between an application and the model introduces a new failure mode , the router itself. LiteLLM is a Python proxy; if it goes down, access to all configured models goes down. In this scenario, teams trade a provider single point of failure for a self-hosted single point of failure with no SLA.
This argument is empirically correct. Router outages cascade to every downstream model. LiteLLM running on a single instance with no redundancy is more fragile than directly calling a provider with a 99.9% SLA. OpenRouter’s managed service partially addresses this , it handles its own redundancy , but adds the token overhead calculated above.
The rebuttal is architectural, not theoretical. Every load balancer, every CDN, every database proxy introduces the same class of risk. The answer is not to avoid routing layers but to treat them as production infrastructure: run LiteLLM in high-availability mode with health checks, deploy multiple instances behind a load balancer, and test failover paths monthly. Teams that skip this rigor should indeed avoid self-hosted routers , they will achieve better reliability with direct API calls to two providers and manual switching than with a poorly maintained proxy (DeployBase).
The Convergence: Why Your Router Reports Savings While Burning Money
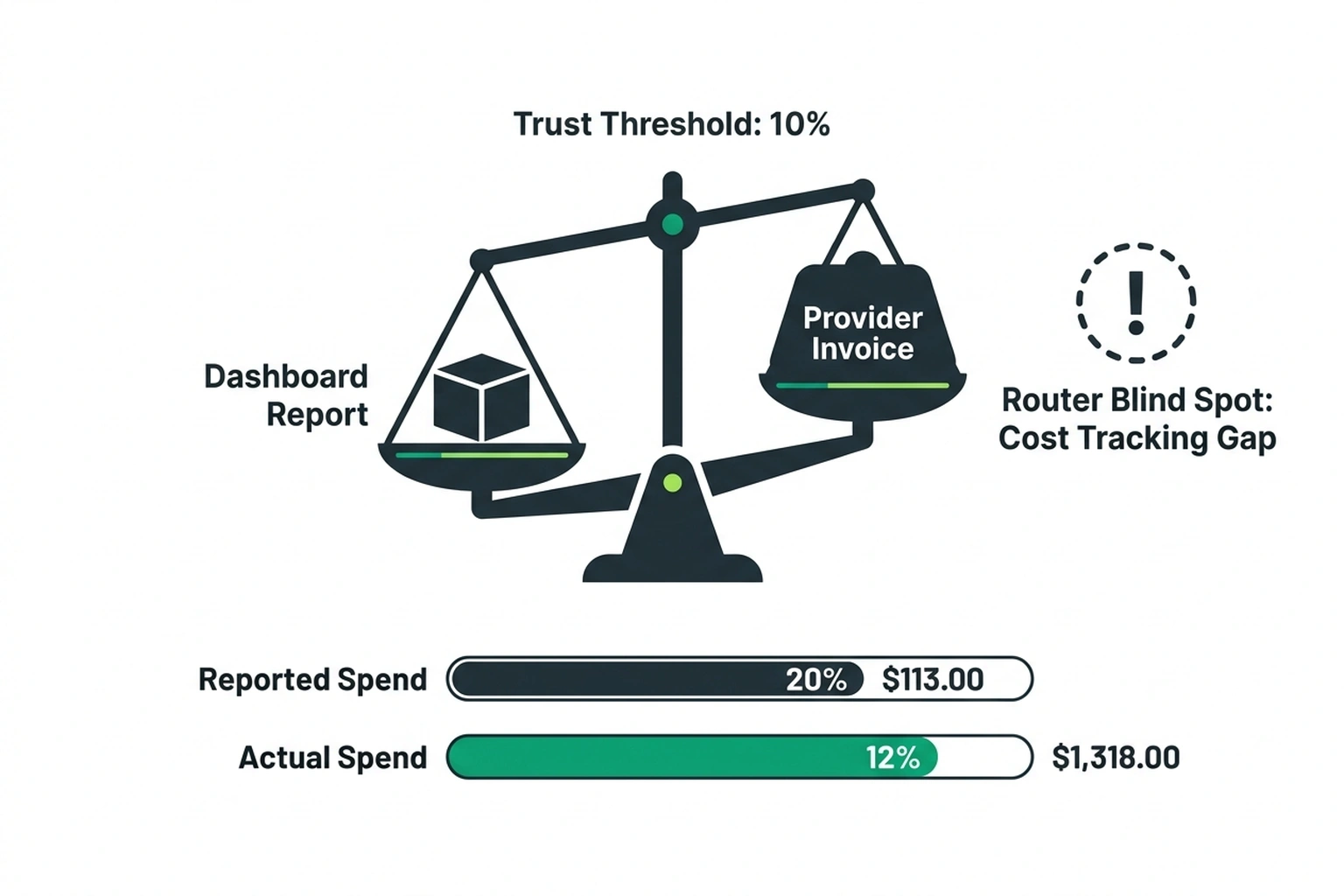
Two independent data points, when combined, produce a conclusion neither contains alone.
Source A: LiteLLM’s GitHub issues show 8-12% cost tracking discrepancies due to provider billing differences (LiteLLM GitHub).
Source B: Many teams cite provider redundancy as their primary routing motivation (Palm Beach Post).
The convergence: A significant number of teams adopted routing for redundancy, configured only the fallback_models parameter, and now operate with cost tracking that is wrong by up to 12%. These teams believe they have cross-provider failover (they do on paper) and believe their cost reports are accurate (they are not). The router’s dashboard shows savings. The provider’s invoice shows higher spend. Neither matches. The gap is where money disappears.
This is the Router Blind Spot , the distance between what the router’s dashboard reports and what the provider’s invoice charges. If that gap exceeds 10%, the router cannot be trusted to make cost optimization decisions. Period.
Fix It This Week: The Token Audit
Stop reading and run this test now. Send a single request through your chosen router. Then compare the token count in the router’s cost log against the token count in your LLM provider’s dashboard. The discrepancy tells you immediately whether your router’s cost tracking is trustworthy enough to make routing decisions on.
For LiteLLM users specifically, check your context_window_fallbacks configuration:
# In your litellm router config
router = litellm.Router(
model_list=[...],
fallback_models=["claude-3-opus", "gpt-4"], # cross-provider
context_window_fallbacks={ # THIS is the parameter that fires on rate limits
"claude-3-opus": ["gpt-4"], # must explicitly cross providers
"gpt-4": ["claude-3-opus"],
}
)
If context_window_fallbacks is not explicitly configured to cross providers, rate limit failures will route back to the same provider that just failed. This is the silent bug in most LiteLLM deployments.
For OpenRouter users, calculate your actual overhead: take your provider dashboard’s token count, subtract the token count in your application logs, and divide by your application’s token count. If the result exceeds 15%, you are paying more in routing tax than you likely save from model selection.
The uncomfortable truth about LLM routing in 2026 is that the tool protecting teams from provider lock-in introduces its own form of dependency. Every router becomes a proxy, every proxy becomes a bottleneck, and every bottleneck becomes a bill. The teams that benefit most from multi-model gateways are those treating routing as infrastructure , with the same rigor applied to load balancers, CDN configuration, and database failover testing. For everyone else, a well-configured fallback to a single alternative model can deliver 80% of the resilience at 20% of the complexity. Run the token audit described above. If the discrepancy between your router’s cost log and your provider’s dashboard exceeds 10%, the router is not saving money , it is hiding costs.
Prediction: By Q4 2026, at least two major LLM routing tools are projected to add native token-overhead transparency dashboards because enterprise customers will demand billing reconciliation between router logs and provider invoices. Cloudflare’s research on routing infrastructure highlights that a properly deployable edge proxy can mitigate these exact overhead issues (Cloudflare Learning Center).
References
- LiteLLM Official Routing Documentation
- LiteLLM GitHub Repository
- DeployBase: “Best LLM Gateway and Router Tools: LiteLLM vs OpenRouter”
- Palm Beach Post: “2026 Agentic AI Era: Why Multi-Model Routing Has Become a Must-Have”
- LLMAPI: “Best OpenRouter Alternatives 2026”
- Evolink: “OpenRouter Alternatives: AI Model Routing 2026”
- Cloudflare: “What is a CDN?”