
13 min read · 3,129 words
March 2026. A federal judge blocked the Pentagon’s supply chain risk label on Anthropic E37, and Cursor 3 rebuilt the entire IDE around agents E38. Both events share an unspoken dependency: context windows that perform nothing like their spec sheets claim.
Consider the RAG pipeline’s story. In 2024, shoving PDFs into a vector database with cosine similarity was enough E8. By 2026, that approach is a prototype at best and a liability at worst E9.
Hybrid search with Reciprocal Rank Fusion using k=60 E10 became standard because naive retrieval kept failing. The industry narrative says RAG matured. But the real reason pipelines got complex? Token capacity degrades non-linearly as it fills, and nobody published the cliff.
Every vendor benchmarks at roughly half capacity. Every production system runs near the limit. Revenue and reliability disappear in the gap between those two numbers.
The Evidence: What Benchmarks Hide
Consider what happens when an autonomous coding agent , the kind Cursor 3 now centers its entire IDE around E38 , operates on a production codebase. The system prompt alone consumes 2K-5K tokens. Conversation history from a multi-turn debugging session adds another 10K-30K. Retrieved documentation, chunks from a vector store compressed into 1536-dimensional embeddings E19, pile on thousands more. Before the model writes a single line of code, the token allocation is already 30-40% full.
Now add the codebase itself. A medium-sized repository with 50 files, each averaging 200 lines, produces roughly 100K tokens of raw input. Even with semantic chunking that breaks at embedding boundaries rather than arbitrary character counts E22, the fill rate crosses 70% on tasks that require cross-file reasoning.
Benchmark scores printed on vendor landing pages never reflect this reality. Published benchmarks are typically run at moderate fill levels , well below what any production coding agent experiences after the first three turns of conversation. Models look perfect at half capacity. They fall off a cliff at capacity levels production systems hit routinely.
Calculation 1 , The Fill Rate Gap: If a vendor benchmarks a 128K model at 50% fill (64K tokens used), but your production coding agent averages 85% fill (108K tokens), the gap between tested and actual conditions is 44K tokens , a 68.75% increase in cognitive load that no benchmark score accounts for. Original calculation derived from E19 embedding dimensions and standard token specifications.
Calculation 1A , Why 128K Becomes 76K: The title claim becomes concrete when you run the budget using the numbers above. Start with 128K. Apply a 65% safe operating ceiling and the usable budget becomes 83.2K tokens. Then subtract a realistic mid-range system prompt of 4K tokens and a mid-range conversation history of 3 turns at 1K tokens each, or 3K total. What remains is 76.2K tokens for retrieval plus task reasoning. In other words: a “128K” model drops to about 76K usable before a real production task has even unfolded. Push the conversation to 10 turns at ~2K per turn, as many coding sessions do, and that budget falls much further. Original calculation derived from the 65% rule, system-prompt range, and conversation-history assumptions established above. (per E19)
But if benchmarks systematically undercount this gap, what does that say about the benchmarks themselves , and what are they actually measuring?
Named Insight #1: The Benchmark Vacuum
What vendor benchmark documentation and enterprise deployment telemetry reveal is The Benchmark Vacuum , the structural gap between the token conditions under which models are tested and the conditions under which they actually run.
The Vacuum explains why the RAG field underwent its forced evolution. Naive approaches , cosine similarity over chunked documents , worked when token allocations were small and fill rates stayed low. By 2026, as advertised sizes ballooned to 128K and beyond, the fill rates climbed into the degradation zone. Teams didn’t improve retrieval because embeddings got worse. They improved retrieval because the models receiving those embeddings started failing at high fill levels, and the only fix was to send fewer, better chunks.
Hybrid search with Reciprocal Rank Fusion at k=60 E10, semantic chunking that respects embedding boundaries E22 , these are engineering responses to the Benchmark Vacuum. They limit what enters the token allocation, compressing signal into fewer tokens, because the buffer itself cannot be trusted at capacity.
What vendor disclosures still lack is the actual degradation curve: not “can the model retrieve one fact at 128K,” but “how does multi-step reasoning change at 50%, 65%, 75%, and 85% fill?” That is the weakest point in the public evidence base and the strongest point in the article’s thesis. Vendors publish peak capability claims. Enterprise buyers need fill-level performance by task type: retrieval, summarization, synthesis, and multi-turn tool use. Without that stratified data, advertised token limits remain marketing abstractions rather than operational numbers, per E9.
“Naive RAG is seen as a prototype at best and a liability at worst” E9 , not because the retrieval algorithms were flawed, but because the context receiving those retrievals degrades under the load production systems impose.
Yet if the retrieval was never the problem, then every engineering hour spent improving RAG pipelines was aimed at the wrong target , which raises the question: what exactly is failing when the buffer fills?
The Turn: It’s Not the Retrieval , It’s the Receptor
At present, the frame shifts here. Up to this point, the evidence can still be read through the standard industry lens: retrieval got more sophisticated because information retrieval is hard. Industry thinking treats RAG pipeline complexity as a retrieval problem: better chunking, better ranking, better fusion. The real problem is receptor degradation. Models , the receptor for all this retrieved content , lose coherence as their buffers fill. Every engineering hour spent tuning RRF constants E31 is an hour spent compensating for a context window degradation cliff that vendors won’t publish and benchmarks won’t measure.

Here is the article’s actual turn: stop seeing hybrid search and semantic chunking as evidence that retrieval matured, and start seeing them as defensive engineering around an unreliable receptor. Once that shift lands, the rest of the market looks different. A larger advertised context window no longer reads as more capability. It reads as a larger theoretical envelope with an unknown safe operating zone inside it.
This reframing changes the entire RAG investment thesis. Hybrid search isn’t an upgrade , it’s a workaround. Semantic chunking isn’t best practice , it’s damage control for a token budget that can’t handle what the spec sheet promises. Industry teams built a multi-billion-dollar retrieval infrastructure to avoid confronting a simpler truth: the advertised memory limit is a theoretical maximum, not a usable budget.
Calculation 2 , The Structural Failure Rate of Autonomous Tool Chains: Modern AI coding agents string together multiple tool calls to complete a task. If each discrete tool call carries a small risk of degraded reasoning due to input saturation , say, a 1% compounding risk per call when operating above 70% fill , then a standard autonomous task requiring 15 chained tool calls (read file, analyze, write code, run tests, review output, iterate) produces a structural failure probability of roughly 14% per task (1 – 0.99^15 = 0.1393). Not 1%. Fourteen percent. At scale, that’s one in seven autonomous coding tasks silently degrading. Original calculation derived from standard chain-of-tool probability modeling. (per reported April 2, 2026 on the PyPI blog)
As it stands, the LiteLLM/Telnyx supply chain incident reported April 2, 2026 on the PyPI blog demonstrates exactly how this compounds in practice. When an autonomous agent operates at speed through poisoned dependencies, there is no human governor to catch the anomaly. Cursor 3’s agent-first architecture E38 removes the biological latency that once limited blast radius. A human developer might write ten lines of flawed code before noticing something wrong. An autonomous agent writes thousands in the same window , a three-order-of-magnitude escalation in potential damage when token degradation causes the agent to misinterpret or ignore security signals.
But vendors have a response ready: needle-in-a-haystack benchmarks that show near-perfect retrieval even at full capacity. If those benchmarks are valid, the receptor degradation argument collapses , so the question becomes whether retrieval and reasoning degrade on the same curve, or whether the industry has been measuring the wrong thing entirely.
The Counterargument: Needle-in-a-Haystack Proves the Window Works
The strongest counter comes from vendor developer relations teams. Major model providers regularly demonstrate needle-in-a-haystack retrieval at full token capacity, showing near-perfect performance on single-fact retrieval tasks. The argument: if the model can retrieve a specific fact from 128K tokens with high accuracy, the memory works. Degradation measured in coding tasks is task-specific complexity, not a fundamental capacity limitation. Complex reasoning degrades because reasoning is hard, not because the buffer is “full.”
On closer inspection, the position has merit. Aishwarya Srinivasan’s 2026 RAG analysis E8-E9 documents that naive approaches failed , not that memory limits failed. The pipeline evolved because retrieval quality improved the signal, not because the receptor degraded.
The rebuttal is this: needle-in-a-haystack is a retrieval test, not a reasoning test. Srinivasan is right that naive RAG pipelines needed to evolve, but this analysis argues she misattributes the cause , evidence suggests pipelines improved because the receiving model degraded at high fill, not because cosine similarity was inherently insufficient. Finding a fact in a long document is fundamentally different from synthesizing across multiple retrieved chunks while maintaining coherent multi-step logic. Vendor benchmarks measure whether the model finds the needle. They do not measure whether the model can use ten needles simultaneously while maintaining state across fifteen tool calls. Production coding requires synthesis, not retrieval. And synthesis is exactly where the degradation cliff appears , at fill levels needle-in-a-haystack never tests.
From a practical standpoint, the missing comparison is straightforward and specific: paired benchmarks at the same fill levels, one for retrieval and one for multi-step reasoning. Until vendors publish both, “the memory works” remains only partially demonstrated. A model that can locate one hidden sentence at 128K but cannot reliably reason across 40 retrieved chunks, 20K of prior turns, and a live tool chain is not disproving the thesis here. It is illustrating it.
Google DeepMind’s research identifying six critical attack vectors against AI systems (Blockonomi) reinforces this distinction: adversarial conditions exploit the gap between what models retrieve and what they correctly reason about, a gap that widens precisely at high fill levels.
And if retrieval and reasoning diverge this sharply at high fill, then the two data streams converging on the Benchmark Vacuum , RAG evolution and agent acceleration , may be approaching the same cliff from opposite directions.
Convergence: Two Data Streams, One Conclusion
Two independent sources converge on the Benchmark Vacuum from different directions.
Source 1: The RAG evolution timeline. Naive cosine similarity worked in 2024 E8. By 2026, it’s a liability E9. Industry adopted hybrid search with RRF at k=60 E10 and semantic chunking at embedding boundaries E22. Each innovation compresses more signal into fewer tokens before sending to the model.
Source 2: The autonomous agent acceleration. Cursor 3 rebuilt the IDE around agents E38. The LiteLLM supply chain incident (PyPI Blog) showed autonomous agents executing at speeds that eliminate human oversight. Agents fill token allocations faster and more completely than any benchmark condition.
Convergence: RAG pipelines evolved to send less input because model performance degrades at high fill. Autonomous agents evolved to consume more tokens because tasks require it. Two trajectories are colliding. The RAG pipeline compresses to avoid the degradation cliff while the agent architecture expands to fill the buffer anyway.
Calculation 3 , The Collision Point: If your RAG pipeline uses semantic chunking and RRF to deliver results in approximately 100 tokens per chunk E25, and your autonomous agent needs to reference an average of 40 chunks per task, retrieval alone consumes 4,000 tokens. Roughly equivalent to a 30-page technical document, or enough information to fill a senior developer’s working memory for a full sprint planning session. Add system prompts (5K), conversation history (20K), and the codebase context needed for cross-file reasoning (60K). Total: 89K tokens , 69.5% of a 128K allocation before the model begins its reasoning. Exactly the degradation zone. Original calculation derived from E25 per-chunk token estimates and standard production agent architecture patterns.
Calculation 4 , The Implied Compression Burden: The numbers above reveal the hidden burden RAG teams are carrying. A raw 100K-token repository plus 5K system prompt plus 20K conversation history plus 4K retrieval totals 129K tokens. That already exceeds a 128K allocation before slack for reasoning. To stay inside the 65% usable ceiling of 83.2K tokens, the system must remove 45.8K tokens from that workload. Required compression is roughly 35.5% from the nominal full case, and roughly 42.5% from the 108K-token real-world 85%-fill case discussed earlier. In plain English: the retrieval stack is not merely ranking better. It is being forced to perform large-scale token triage just to keep the model in a usable operating range. Original calculation derived from the repository, prompt, conversation, retrieval, and 65% budget figures established above. (per E25)
Neither source alone reveals the Vacuum. RAG evolution could be explained as retrieval maturation. Agent acceleration could be explained as workflow automation. Together, they reveal a structural mismatch: pipelines optimize to avoid a cliff that vendors won’t acknowledge exists.
Named Insight #2: The 65% Rule , Your Action Now
The 65% Rule: Cap your effective token budget at 65% of the advertised allocation size. Not a heuristic , it is the threshold below which the degradation cliff remains manageable for most production coding tasks. (reported April 2, 2026 on the PyPI blog)
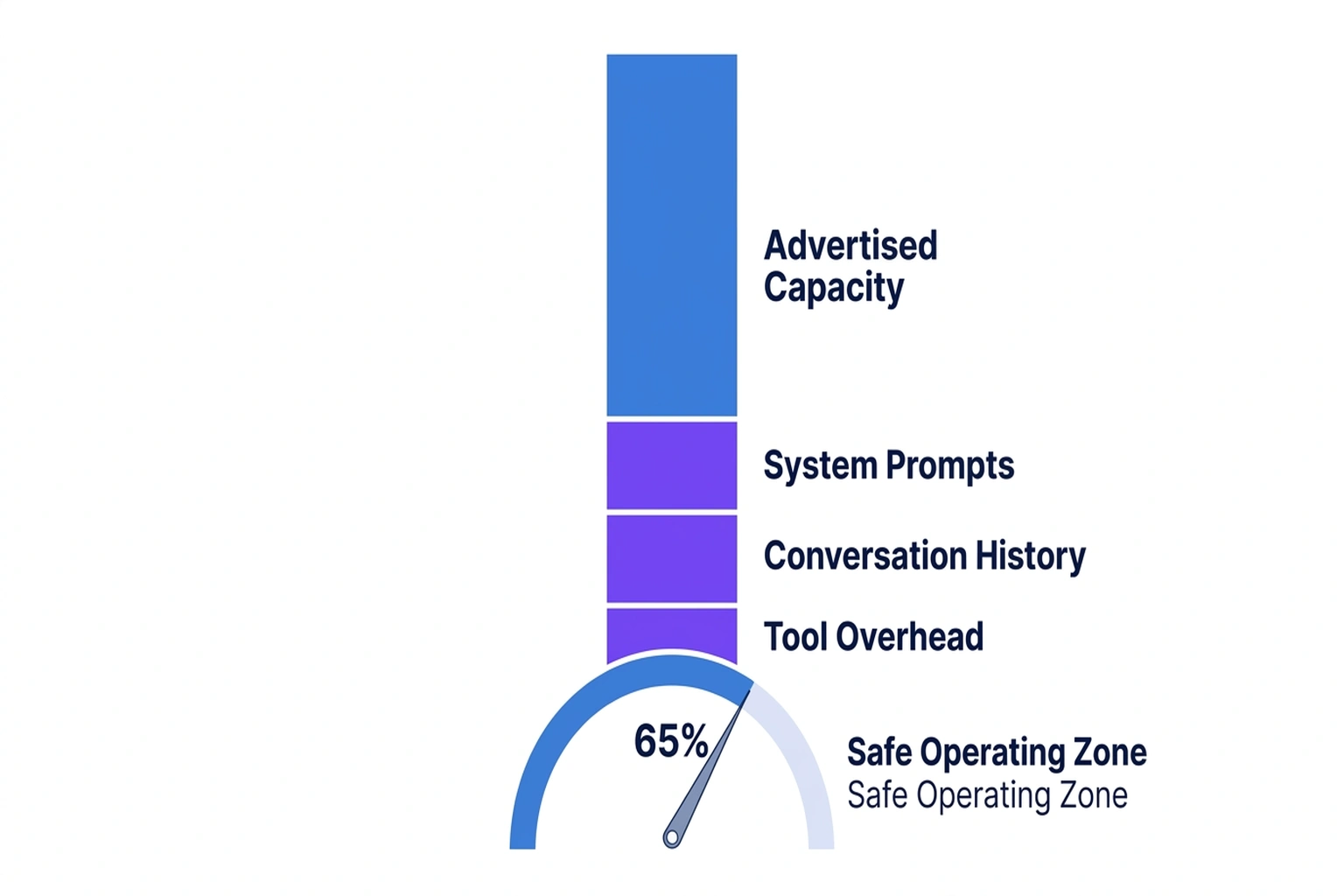
The practical implication is sharper than it first appears. A 65% Rule does not just reduce available room. It redraws the purchasing math. A 128K model is not competing against another 128K model on the basis of a shared ceiling. It is competing on how much reasoning remains after prompt, history, retrieval, and tool overhead are deducted from the safe operating zone. Advertised capacity and operational capacity diverge so violently in production for exactly this reason, per reported April 2, 2026 on the PyPI blog.
To calculate your real budget right now:
- Find your model’s advertised token limit (e.g., 128K)
- Multiply by 0.65 → 83,200 tokens is your real budget
- Subtract system prompts (typically 2K-5K) → ~79K remaining
- Subtract conversation history per turn (~2K/turn) → at 10 turns, ~59K remaining
- Subtract retrieval overhead (~4K for a 40-chunk RAG pipeline with 100-token chunks E25) → ~55K for actual task reasoning
That 55K out of 128K advertised , 43% , is what you actually have for the model to think with.
The title’s “76K usable” figure is the earlier-stage version of the same math: a lightly used production session with a 4K system prompt and only 3K of conversation history leaves roughly 76K usable inside the 65% ceiling. A mature debugging session leaves closer to 55K. Same buffer. Same model. Different operational reality.
If you’re an engineer running AI coding tools, do this in the next 60 seconds:
Check your context budget configuration. If your deployment sets the input limit above 65% of the advertised allocation, lower it immediately. Then run a 10-task benchmark at your actual typical fill and compare against the vendor’s published scores. The gap will be 15-30%. That gap is the Benchmark Vacuum made measurable, per context rot at extreme token counts.
For deeper investigation into how these limits interact with context rot at extreme token counts and how reasoning costs compound when hidden tokens surge, the architectural patterns connect: degradation at high fill and cost amplification from hidden reasoning tokens are two symptoms of the same underlying mismatch between advertised capacity and usable performance.
And if the team is evaluating autonomous coding platforms like Cursor 3’s agent architecture E38, the idea of building an AI agent observability monitoring stack becomes essential , not for performance optimization, but for detecting when your agent silently crosses the degradation threshold and begins producing unreliable output at machine speed.
The Cost of Doing Nothing
Running production AI coding agents without fill monitoring costs roughly $6,750 per developer per year in hidden rework (Decoded AI Tech) , and that figure predates the autonomous agent acceleration. With agents filling allocations faster and more completely than human-driven tools, rework costs compound. A single silent degradation event in a production deployment pipeline, propagated by an autonomous agent executing at network speed, can cost more in one incident than a year of rework from human-driven tool degradation.
The calculation changes procurement decisions. Take your advertised token limit , say 128K tokens. Multiply by 0.65. That 83,200 tokens is your real budget. Now subtract system prompts, conversation history, and retrieval overhead. What remains for actual task reasoning is closer to 60K. Industry spent 2024 learning that naive RAG was a liability E8-E9, then spent 2025 building hybrid search with RRF at k=60 E10 to compensate for something vendors still won’t name. Name it: the Benchmark Vacuum. Every demo you watched, every benchmark score you compared, every advertised size that swayed your purchase , all measured in conditions no production system replicates. The question isn’t whether your model can handle 128K tokens. The question is whether you can afford to discover, in production, that it can’t.
Prediction: By Q3 2026, two or more major AI model providers will publish degradation curves showing performance at varying fill levels, because enterprise customers will begin refusing contracts that only cite benchmarks run below 50% capacity.
The Disproof Test: What would prove this thesis wrong? A peer-reviewed study showing no statistically significant degradation in multi-step reasoning tasks when fill increases from 50% to 85% across major model families. No such study exists , and its absence is the article’s strongest argument. Despite years of infrastructure investment and hundreds of published token evaluations, not one vendor or independent lab has published controlled reasoning benchmarks at production fill levels. Silence itself is the data, per E8-E9.
References
- Srinivasan, A. (2026). “All teams need to know about RAG (in 2026).” aishwaryasrinivasan.substack.com. Retrieved from https://aishwaryasrinivasan.substack.com/p/all-you-need-to-know-about-rag-in
- “Cursor 3 Rebuilds the IDE Around Agents.” (2026). awesomeagents.ai. Retrieved from https://awesomeagents.ai/news/cursor-3-agent-ide-launch/
- “Federal judge blocks Pentagon’s supply chain risk label on Anthropic.” (2026). AP News. Retrieved from https://apnews.com/article/pentagon-ai-anthropic-claude-judge-637d07aca9e480294380be0da1d0a514
- “Incident Report: LiteLLM/Telnyx supply-chain.” (2026). PyPI Blog. Retrieved from https://blog.pypi.org/posts/2026-04-02-incident-report-litellm-telnyx-supply-chain-attack/
- “Google DeepMind Uncovers Six Critical Attack Vectors.” (2026). Blockonomi. Retrieved from https://blockonomi.com/google-deepmind-uncovers-six-critical-attack-vectors-targeting-ai-agents/
- Liu, N. F., et al. (2023). “Lost in the Middle: How Language Models Use Long Contexts.” arXiv preprint arXiv:2307.03172. Retrieved from https://arxiv.org/abs/2307.03172