
13 min read · 3,292 words
Affiliate Disclosure: This article contains affiliate links. We may earn a commission if you purchase through these links, at no additional cost to you. This helps us continue publishing free content. See our full disclosure.
When Polar Coordinates Panic Wall Street
A paper about converting mathematical vectors into polar coordinates wiped billions from memory chip stocks in days, before a single line of that code ran on a production server.
On March 24, Google researchers Amir Zandieh and Vahab Mirrokni published TurboQuant, an AI compression algorithm targeting the KV cache that achieves a 6x reduction with zero accuracy loss (arXiv; Google Research). Four days of trading erased billions in market capitalization across SK Hynix, Samsung, SanDisk, and Micron (The Korea Times; Investing.com; Benzinga). The paper had not been presented, peer-reviewed at its conference, or deployed anywhere. Markets moved on a preprint.
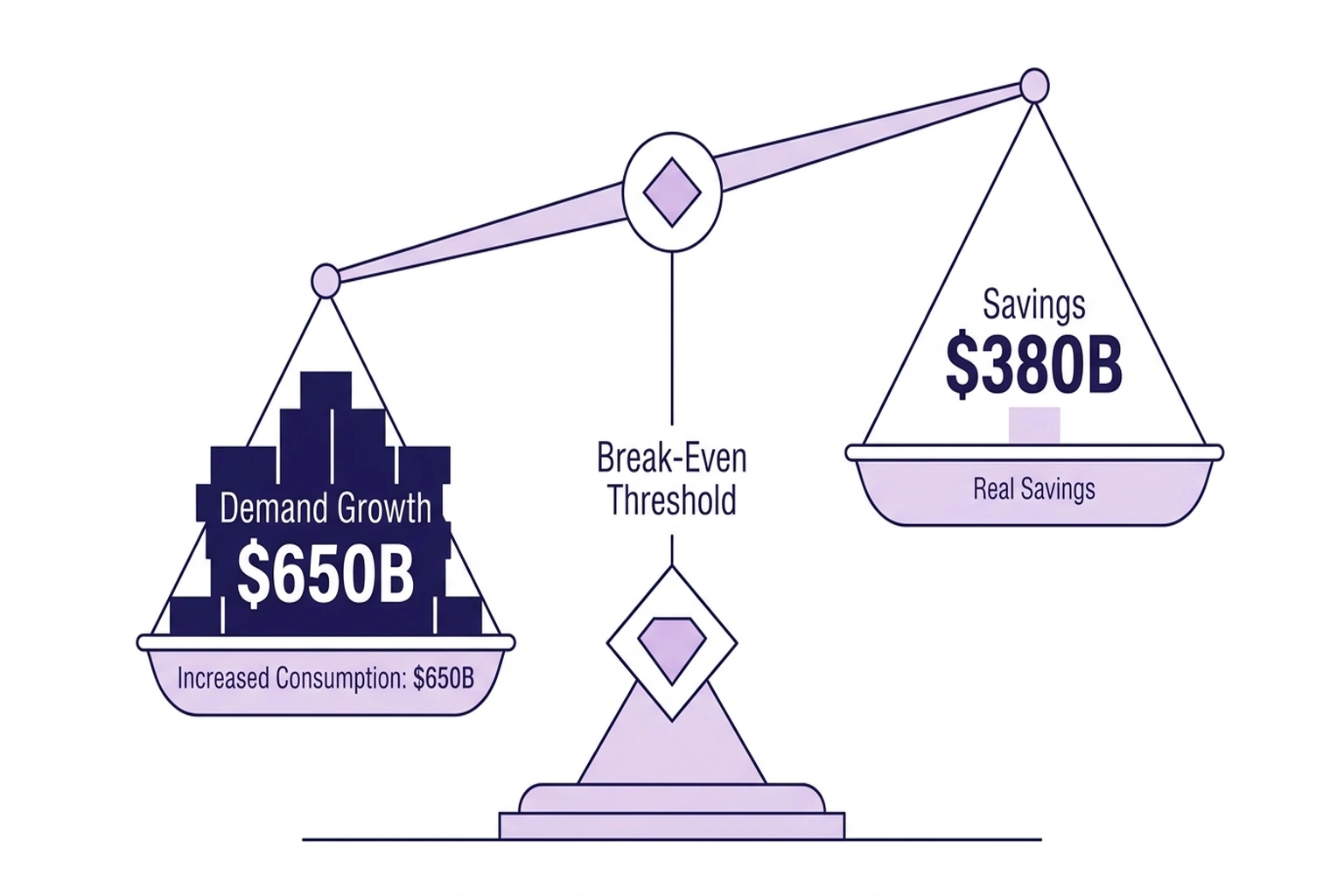
Beneath the sell-off sat a clean thesis: if software compresses AI memory 6x, the $650 billion infrastructure buildout, roughly $1,900 for every person in the United States, needs far less hardware. Straightforward arithmetic.
Except that arithmetic contains a variable every sell-side model set to zero, and to see it, you have to look at where the compression actually lands.
Inside the Compression, and the Paradox It Creates
Most AI infrastructure spending funds model weights and training clusters. TurboQuant touches neither.
It targets the key-value cache, the memory buffer that grows with every token during inference. KV cache is irrelevant during training. It matters only during the revenue-generating phase: serving users, answering questions, processing documents. The sell-off priced in a training-era cost reduction. TurboQuant operates in the inference era, where cheaper capacity creates demand.
“As context windows get bigger and bigger, the data storage in KV cache explodes higher causing the need for more memory,” said Andrew Rocha, TMT Analyst at Wells Fargo (Investing.com). “TurboQuant is directly attacking the cost curve here.”
SK Hynix fell 6.23%, Samsung shed 4.71% (The Korea Times; Investing.com), and SanDisk dropped 5.7%. Micron, however, bled over 20% across four sessions, its worst streak since the April 2025 tariff shock (Benzinga). The sell-off punished the HBM3 pureplay four times harder than diversified manufacturers, pricing in fewer GPUs rather than smaller caches.
Mechanically, TurboQuant stacks two techniques. PolarQuant converts vectors to polar coordinates, the transformation that spooked Wall Street. QJL adds 1-bit error correction via the Johnson-Lindenstrauss Transform, requiring zero memory overhead (SiliconANGLE). Google’s benchmarks across Gemma, Mistral, and Llama model families produced “perfect downstream results”, 6x compression at 3 bits with zero accuracy penalty (Google Research).
Both claims hold up in the published benchmarks. But Rocha’s framing, ”attacking the cost curve”, deserves pushback. A company doubling infrastructure spending to approximately $180 billion does not compress to save money (Yahoo Finance; Benzinga). It compresses to unlock workloads that were previously impossible.
Rocha is right that TurboQuant attacks the cost curve, but wrong about the consequence. Attacking a cost curve in a market with elastic demand doesn’t reduce spending. It moves the frontier.
And the frontier is where the numbers matter most. On an 8-billion-parameter model at 32,000 tokens, KV cache consumes approximately 4.6 GB of GPU memory, roughly 22% of total inference footprint. Scale to 128,000 tokens: 18.4 GB, or 53% of total memory. Scale to 1 million tokens, the context demanded by full-codebase analysis, multi-document workflows, and persistent AI agents, and the cache balloons to approximately 144 GB, per Yahoo Finance.
The Addressable Ceiling
These percentages expose the sell-off’s first arithmetic error, not in direction, but in magnitude.
Three variables define the maximum damage TurboQuant can inflict on memory demand. Inference accounts for an estimated 30–40% of total AI GPU deployment; the rest is training, fine-tuning, and research where KV cache does not exist. KV cache itself represents 22% of inference memory at short contexts, scaling to 53% at the 128K-token lengths now entering mainstream deployment. TurboQuant’s 6x compression eliminates five-sixths of that cache, an 83% reduction on the slice it touches. (Investing.com)
Multiply through:
| Scenario | Inference share | KV cache share | Compression savings | Max demand reduction |
|---|---|---|---|---|
| Conservative (short-context-weighted) | 30% | 25% | 83% | 6.2% |
| Moderate (mixed workloads) | 35% | 35% | 83% | 10.2% |
| Aggressive (long-context-weighted) | 40% | 53% | 83% | 17.6% |
Even the aggressive scenario, which assumes every inference workload runs at 128K tokens, a context length most production systems have not yet reached, yields a ceiling of 17.6% of total HBM demand. The moderate case, closer to the industry’s actual workload distribution, caps at 10%. (Benzinga)
These numbers assume three conditions holding simultaneously: instant universal adoption, zero demand elasticity, and every inference provider deploying TurboQuant before procurement cycles adjust. None is realistic. The paper has not shipped in production. Semiconductor lead times lock orders quarters ahead. And no efficiency gain in the history of computing has produced zero demand response.
Micron dropped 20% in four sessions. The market priced in a demand shock that exceeds the theoretical ceiling, under assumptions that cannot all hold at once.
But this analysis argues the sell-off’s deeper error was not overpricing the savings. It was computing on the wrong side of the equation.
The Turn
One number collapses the savings thesis entirely: a single NVIDIA H100 has 80 GB of HBM3.
Without compression, million-token inference requires two H100s for KV cache alone, before model weights claim a byte. The workloads that every hyperscaler is racing to build, full-codebase agents, document-scale reasoning, multi-session memory, cannot run on today’s hardware at the context lengths they require.
With TurboQuant’s 6x reduction: 144 ÷ 6 = 24 GB. Million-token inference fits on a single GPU with 56 GB to spare.
Compression doesn’t save a GPU. It eliminates the need for a second one while making million-token inference possible on a single card for the first time. The memory chips are not redundant. They are, for the first time, sufficient.
This dynamic is worth naming: the Jevons Cache. Efficiency gains targeting the KV cache make previously impossible context lengths feasible. Feasible capabilities, in an industry burning through $650 billion to find competitive advantage, get adopted. Adopted capabilities consume hardware, per how inference economics actually work in production.
Wall Street saw the Addressable Ceiling, savings in the single digits, and priced in catastrophe. It missed the Jevons Cache entirely: the demand created on the other side of that same compression. And the calculations that quantify that demand are the ones the sell-off never ran.
Three Calculations the Sell-Off Missed
Calculation 1: The inventor’s bet. Every memory stock model treats efficiency as a numerator reduction: compress 6x, need 6x fewer chips. That math ignores how inference economics actually work in production.
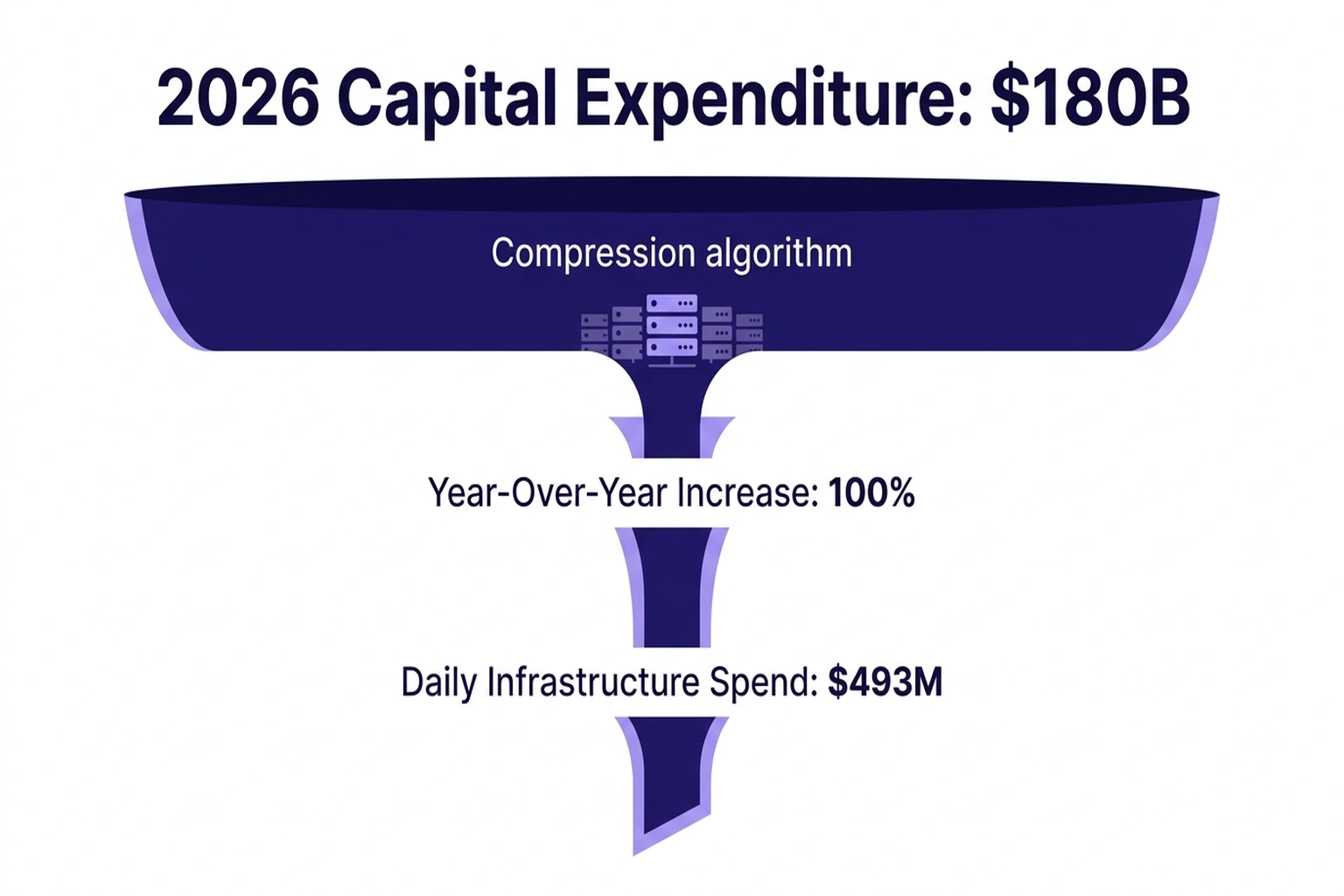
Google published TurboQuant while simultaneously raising 2026 capital expenditure to approximately $180 billion, a 100% year-over-year increase (Yahoo Finance; Benzinga). That is roughly $493 million per day in infrastructure spending from the company that built the AI compression algorithm. If Google’s own researchers believed TurboQuant would slash memory demand, the capex guidance would reflect it. It doubled instead.
Calculation 2: The nonlinear unlock. TurboQuant’s AI compression ratio is a constant. Its impact is not. At short contexts, KV cache is a minor line item, compressing it saves pocket change. At million-token contexts, KV cache is the infrastructure cost. TurboQuant’s efficiency gain concentrates at precisely the frontier where new workloads emerge: full-codebase agents, document-scale reasoning, multi-session memory. And long-context inference is where hidden cost multipliers already stack. Compression that only matters at the capability frontier is not a cost reduction. It is a capability expansion wearing a compression label.
Calculation 3: The throughput multiplier. The first two calculations operate at the industry level. This one operates at the GPU level, where compression converts directly into concurrent capacity.
Take a single H100 (80 GB HBM3) serving an 8-billion-parameter model at 128K context. Model weights occupy 16 GB. Available for KV cache: 64 GB. Each concurrent inference stream requires 18.4 GB of KV cache.
Without compression: 64 ÷ 18.4 = 3 concurrent streams per GPU.
With TurboQuant: each stream’s KV cache drops to 18.4 ÷ 6 = 3.07 GB. Available capacity: 64 ÷ 3.07 = 20 concurrent streams per GPU.
Same chip. Same card. Same HBM3 that SK Hynix manufactured and the market just marked down. Based on the calculations in this analysis, 6.7x more users can be served simultaneously. Every memory chip already installed becomes 6.7x more productive at long contexts, not because it needs replacement, but because the software constraint that throttled it just disappeared.
Now multiply by the industry’s inference fleet and ask the question the sell-off avoided: will AI inference demand grow less than 6.7x?
In a market where every hyperscaler is racing to ship AI agents, document-scale processing, and persistent assistants, backed by $650 billion in committed capex (Yahoo Finance), where Meta alone committed $27 billion in a single compute capacity deal (The Next Web), the question answers itself. TurboQuant did not free up capacity. It opened a 6.7x gap between what each GPU can now serve and the demand that feasibility just unlocked.
At present, the Addressable Ceiling says the maximum savings were always single digits. The throughput multiplier says the demand response will be measured in multiples. One of these numbers panicked the market. The other one hasn’t been priced in yet.
The Strongest Counter. Steelmanned
Kim Rok-ho, Analyst at Hana Securities, made the sharpest bearish argument, and it deserves its strongest framing: “Compression technologies are not new, and it remains uncertain whether they will be widely adopted” (The Korea Times). KIVI, a KV cache quantization method presented at ICML 2024 (Liu et al., arXiv), delivered measurable compression gains, yet no documented case of reduced memory procurement followed.
Standard semiconductor lead times reinforce Kim’s skepticism. HBM3 orders for Q3 2026 would have been placed months before TurboQuant’s publication. A paper scheduled for ICLR presentation in late April, deployed in production optimistically by Q4, cannot affect hardware already on loading docks (Benzinga). Short-term demand destruction is not just unlikely, it is logistically impossible.
But Kim’s own framing undermines the sell-off’s thesis. If adoption will be slow, as every prior quantization method suggests, then impact on memory demand will also be slow. Markets priced in immediate structural demand reduction. Kim’s analysis suggests nothing of the sort. Calling TurboQuant an incremental advance is precisely the argument that compression will not destroy the demand curve.
Kim’s KIVI precedent also cuts against his own position, and toward this article’s thesis. If the Jevons Cache applies to AI compression, why didn’t KIVI produce visible demand growth? Because KIVI’s compression ratio was modest, and it shipped before million-token contexts became the competitive frontier. A 2x gain on a 32K-token workload saves memory. A 6x gain that makes million-token inference fit on a single GPU, turning 3 concurrent streams into 20, crosses a capability threshold. Jevons effects require the efficiency gain to unlock something previously impossible, not merely make something cheaper.
What specific evidence would disprove the Jevons thesis for TurboQuant? A direct measurement showing AI inference price elasticity (ε) below 1.0, meaning cheaper inference does not proportionally increase consumption. No such measurement exists. No published study has isolated the price elasticity of AI inference demand; the market is scaling too rapidly for any estimate to stabilize. KIVI, grouped query attention, and multi-query attention all shipped without producing measurable demand reduction. The absence of a single documented case where compression reduced total hardware consumption, across a decade of efficiency gains, is the finding.
Markets priced in revolution. The evidence suggests evolution. Both conclusions favor recovery.
The Jevons Break-Even: An This compression approach Framework
Vivek Arya, Semiconductor Analyst at BofA Securities, turned the demand-side math into a testable claim: “The 6x improvement in memory efficiency … is likely to produce a 6x increase in accuracy and/or context length, rather than a 6x decrease in memory” (Benzinga). That reframing leads to a formula.
The Jevons Break-Even quantifies the threshold where Compression techniques stops saving money and starts increasing demand: (TurboQuant: Redefining AI Efficiency wit)
Net demand change = E^(ε − 1)
Where E = efficiency gain (6 for TurboQuant) and ε = price elasticity of AI inference demand. At ε = 1.0, net demand is unchanged, break-even. Above 1.0, efficiency paradoxically increases total consumption. Below 1.0, compression delivers real savings.
Every observable signal points to ε well above 1.0. Hyperscaler capex is growing to an estimated $650 billion in 2026 (Yahoo Finance), long-context workloads are the fastest-growing inference category, and model providers compete on context length. At ε = 1.5: TurboQuant’s 6x compression produces 6^0.5 = 2.45x more total memory demand. At ε = 2.0: 6x more, as if compression never happened.
As it stands, the throughput multiplier from the previous section provides a cross-check. At 128K context, TurboQuant converts each GPU from 3 to 20 concurrent streams, a 6.7x capacity expansion. For total memory demand to merely stay flat, inference consumption would need to remain below that 6.7x headroom while every hyperscaler actively ships the workloads that fill it. The Jevons Break-Even formula and the throughput calculation converge on the same conclusion from different directions: the sell-off’s demand model requires an elasticity that no observable market behavior supports.
Run the spreadsheet. If the result surprises, that is exactly why the sell-off happened.
| Stakeholder | Signal | Action This Quarter |
|---|---|---|
| Inference operators | KV cache >40% of GPU memory at long contexts | Profile memory allocation per context length; request quantized KV support from providers, the freed capacity is free throughput |
| Memory chip investors | Capex growth (100% YoY) outpaces compression ratio | Track hyperscaler capex revisions, not compression papers, procurement orders are the leading indicator |
| Model providers | Compression cuts long-context serving costs | Ship context-length differentiation now, the cost barrier just dropped and competitors noticed |
For CTOs: deferral is not advisable GPU procurement on the assumption that compression will reduce fleet requirements. Model TurboQuant as a context-length multiplier, 3 streams to 20 per GPU at 128K, and plan capacity for the workloads it enables. For CFOs: the relevant line item is not “hardware savings from compression” but “revenue from workloads that compression makes feasible for the first time.” Run the Jevons Break-Even formula against your own inference elasticity before cutting capital requests. (Google’s TurboQuant compresses AI)
Cost of inaction: For each always-on million-token inference stream, the delta between compressed and uncompressed KV cache equals one H100. At your cloud provider’s rate R, that gap compounds to R × 8,760 per year. At $3/GPU-hour , a mid-range across providers like RunPod, which offers on-demand H100 instances for long-context inference workloads , a team running four concurrent long-context streams leaves approximately $105,000 per year in GPU capacity stranded. Compression doesn’t just save that money; it converts stranded memory into revenue-generating throughput.
Prediction: By Q4 2026, HBM3 demand is projected to exceed pre-TurboQuant analyst consensus. Memory stocks that fell 5–20% on the announcement will trade above their March 24 levels by December, because long-context inference workloads will absorb efficiency gains faster than procurement adjusts. Track SK Hynix and Micron quarterly guidance against this benchmark.
How to Apply This Before the Next Model compression Paper Drops
Step 1: Run the Jevons Break-Even for your demand curve. Apply the formula (Net demand change = E^(ε − 1)) using your workload’s price elasticity. If cutting inference cost by half would more than double your query volume, because users or products would consume longer contexts, enable new agentic workflows, or serve additional concurrent sessions, your ε exceeds 1.0 and compression will increase your total hardware needs, not decrease them. Most production inference operators sit firmly in this territory: every context-length expansion to date has unlocked net-new workloads that consumed more capacity than the efficiency gain freed.
Step 2: Pressure-test sell-offs against semiconductor lead times. HBM3 orders for the next two quarters are already locked. Any This compression approach technique published today cannot affect chips already manufactured and allocated. If a stock drops on a paper that has not yet been deployed in production, the market is pricing in a timeline that semiconductor logistics do not support. That gap between market reaction and supply-chain reality is where mispricing lives.
Step 3: Run the throughput multiplier on your own fleet. Calculate your current concurrent inference streams per GPU at your dominant context length. Apply TurboQuant’s 6x to the KV cache component only. The ratio between new capacity and current utilization is your demand headroom, the gap compression opens before you need a single additional chip. If your product roadmap fills that headroom within four quarters, compression is a growth catalyst, not a cost reduction.
According to arXiv, Step 4: Follow procurement orders, not arxiv abstracts. Hyperscaler capital expenditure signals where memory demand is heading. When Google doubles capex to approximately $180 billion in the same quarter it publishes a 6x Compression techniques algorithm, the company that built the compression is buying more hardware, not less. The sell-off followed the paper. The money followed the opposite direction.
What the Coordinates Were Measuring All Along
Polar coordinates do not destroy information. They transform geometry, radii and angles instead of x-y positions, while preserving every relationship in the data.
TurboQuant reshapes how memory gets used, not how much gets consumed. Rocha at Wells Fargo saw the cost curve attack. Arya at BofA saw the capability unlock. Both examined the same polar coordinates. Only one of them noticed the demand on the other side.
According to Google Research, the Addressable Ceiling says the damage was always capped at single digits. The throughput multiplier says the opportunity is measured in multiples. The Jevons Break-Even says demand elasticity decides which number wins, and every dollar of the $650 billion spending plan points in one direction.
According to The Korea Times, a coordinate-geometry paper scheduled for a machine learning conference crashed the world’s largest memory chip stocks. Nothing in that paper supports the sell-off’s thesis. Every dollar of the spending plan contradicts it. And the company that invented the Model compression algorithm is spending $493 million per day to prove it.
Note: this analysis relies on company-reported capex guidance and analyst estimates, which may be revised. The Addressable Ceiling calculation uses industry estimates for inference share of total GPU deployment (30–40%); actual splits are not publicly reported and vary by provider. TurboQuant has been benchmarked on open-source models in controlled settings; production performance across proprietary architectures and at hyperscaler throughput remains unverified.
What to Read Next
- GPT-5.4 Mini vs Nano: Small Model Costs Hide a 33-Point Cliff
- Qwen 3.5 Benchmark Win Hides a 15th-Place User Verdict
- Helios Turns a $400 GPU Into a Real-Time AI Video Studio
References
- TurboQuant (arXiv:2504.19874) , Original research paper by Amir Zandieh and Vahab Mirrokni, published as a preprint prior to ICLR 2026 presentation
- TurboQuant: Redefining AI Efficiency with Extreme Compression , Google Research blog detailing the algorithm, benchmarks, and ICLR 2026 presentation
- Google’s TurboQuant unlikely to weaken memory demand: analysts , Korea Times roundup of Samsung Securities and Hana Securities analyst perspectives
- MU, WDC, SNDK fall: Why Google’s TurboQuant is rattling memory stocks , Investing.com with Wells Fargo and Lynx Equity Strategies analysis
- Micron Stock’s Rally Looked Unstoppable , Until TurboQuant Hit , Benzinga with BofA Securities and Morgan Stanley analyst responses
- Google develops TurboQuant compression technology , SiliconANGLE technical breakdown of PolarQuant and QJL mechanisms
- Big Tech set to spend $650 billion in 2026 , Yahoo Finance individual company capex breakdowns
- Google’s TurboQuant compresses AI memory by 6x, rattles chip stocks , The Next Web with Meta’s $27 billion compute deal context