
8 min read · 2,078 words
Affiliate Disclosure: This article contains affiliate links. We may earn a commission if you purchase through these links, at no additional cost to you. This helps us continue publishing free content. See our full disclosure.
When Check Point Research disclosed CVE-2025-61260, the disclosure was blunt: OpenAI’s Codex CLI (Command Line Interface) had shipped with a command injection flaw in its MCP (Model Context Protocol) server configuration that allowed repository files to trigger arbitrary code execution (Check Point Research). By November 2025, Anthropic had documented a two-layer sandbox for Claude Code, enforcing filesystem and network isolation at the OS kernel level (InfoQ). Between those two disclosures, AI coding assistant security split along architectural lines that most development teams have not yet mapped, and the evidence trail since then makes the divergence measurable.
Two Architectures, Two AI Coding Assistant Security Models
Codex CLI launched with what security researchers describe as a helpfulness-first orientation, prioritizing task completion speed and granting broad access to the local filesystem and shell. BankInfoSecurity reported that the tool’s file-processing pipeline could execute hidden commands embedded in repository files, bypassing its permission model entirely (BankInfoSecurity). Claude Code took a different path from the start: a two-layer sandbox restricting both filesystem access and network connectivity using Seatbelt on macOS and bubblewrap on Linux, as detailed in Anthropic’s official documentation (Claude Code Documentation).
That architectural gap matters because the dominant attack vector against AI coding assistants in 2025-2026 is not direct model exploitation. A January 2026 study published on arXiv found that indirect prompt injection, where malicious instructions hide in repository files, GitHub issues, or pull request comments, achieved attack success rates exceeding 85% against several published defenses (arXiv 2601.17548v1). Attackers do not need to compromise model weights. A poisoned repository file is sufficient to weaponize the agent itself.
Codex Security Vulnerabilities in the Record
CVE-2025-61260 exposed a specific weakness in Codex CLI’s trust boundary: its handling of MCP server configurations could be manipulated to execute arbitrary commands the moment a developer initialized the tool against a repository containing a crafted configuration file, with no visible prompt or user confirmation (Check Point Research). Techzine’s analysis confirmed the MCP configuration as a dangerous gap, noting that the vulnerability allowed silent code execution before any user interaction occurred (Techzine).
OpenAI responded with Codex Security, a separate scanning tool released in research preview designed to detect vulnerabilities in code that Codex generates, not to harden the CLI’s own execution environment against adversarial inputs (OpenAI). For teams evaluating The security of these assistants posture, that distinction is significant: Codex now ships both a code generation tool and a scanner for that tool’s output, acknowledging implicitly that generated code cannot be treated as trusted.
NVIDIA’s AI red team published a complementary finding in early 2026: agentic developer tools that process GitHub pull requests and issues are susceptible to indirect prompt injection attack chains, where an attacker’s payload travels from a code review comment through the agent’s context window and into executed shell commands (NVIDIA Developer Blog). Teams running Codex in automated review pipelines, including those evaluating GPT-5.4’s expanded agent capabilities, should treat this vector as active and present.
Claude Code Security Features and Blind Spots
Anthropic’s engineering team documented Claude Code’s sandbox as a two-layer system: an inner layer restricting filesystem reads and writes to explicitly approved directories, and an outer layer controlling network access through OS-level enforcement (Anthropic Engineering). InfoQ’s coverage of the November 2025 release noted the architecture was designed to reduce blast radius, if a malicious instruction reaches the model through injected context, the sandbox constrains what the model can actually execute on the host system (InfoQ).
Claude Code is not immune to prompt injection. Lasso Security published an analysis identifying four categories of indirect prompt injection attacks capable of reaching Claude Code’s context through repository files, documentation, and dependency manifests (Lasso Security). Lasso’s team released an open-source detection tool with over 50 regex patterns targeting these injection vectors, evidence that the sandbox limits damage but does not prevent the injection itself. In the arXiv comparative study, Claude Code received a “low” vulnerability classification, yet researchers documented successful attacks in scenarios where malicious content was embedded in files the tool was explicitly asked to process (arXiv 2601.17548v1).
Claude Code’s architecture assumes that better model training reduces insecure output at generation time. Codex Security assumes that all generated code should be scanned regardless of training quality. this divergence the Sandbox-Scanner Dilemma , two mutually incomplete approaches to a problem that requires both. Sandboxing constrains what malicious input can DO; scanning constrains what generated output can BECOME. Neither alone addresses the full attack chain from injected input to committed code.
Quantify the exposure. Endor Labs reports 2.74× more vulnerabilities in AI-generated code versus human-written code (Endor Labs). A team generating 1,000 lines of code daily via AI assistants , conservative for an enterprise deployment , introduces roughly 2.74× the vulnerability density of manual coding. If 62% of AI solutions contain design flaws and the average critical vulnerability costs $4.44 million to remediate via breach, a team committing 250 AI-generated PRs per month with even a 1% critical flaw rate faces 2.5 potential breach vectors per month. Annualized: 30 potential entry points, each carrying multi-million-dollar exposure.
Cost of inaction for teams not auditing AI-generated code: every unscanned PR is a lottery ticket for a supply chain attack. At 2.74× vulnerability density and no secondary scanning, the expected time to first exploitable vulnerability entering production is measured in weeks, not months.
Prompt Injection Resistance: Head-to-Head
The arXiv study offers the most direct comparative data available. Researchers tested multiple AI coding assistants against identical prompt injection payloads embedded in workspace files, GitHub issues, and documentation, then classified results by severity (arXiv 2601.17548v1).
Supply chain exposure compounds these results in ways neither sandboxing nor scanning fully addresses. Snyk’s February 2026 ToxicSkills audit examined 3,984 AI agent skills on ClawHub and reported that 36.82% contained security flaws, with 91% of identified malicious skills combining prompt injection with secondary payloads like credential harvesting or data exfiltration (Snyk). Teams that previously evaluated AI agent sandboxing approaches now face a second question: not just whether the agent is contained, but whether its extensions are clean.
AI Code Generation Risks: What the Tools Produce
Beyond each tool’s own attack surface, Coding tool security extends to the code these tools write. Georgetown University’s Center for Security and Emerging Technology (CSET) published a November 2024 report identifying three risk categories: insecure code patterns generated directly, model vulnerabilities exploited through poisoned training data, and feedback loops where insecure generated code enters future training sets and amplifies the problem (Georgetown CSET).
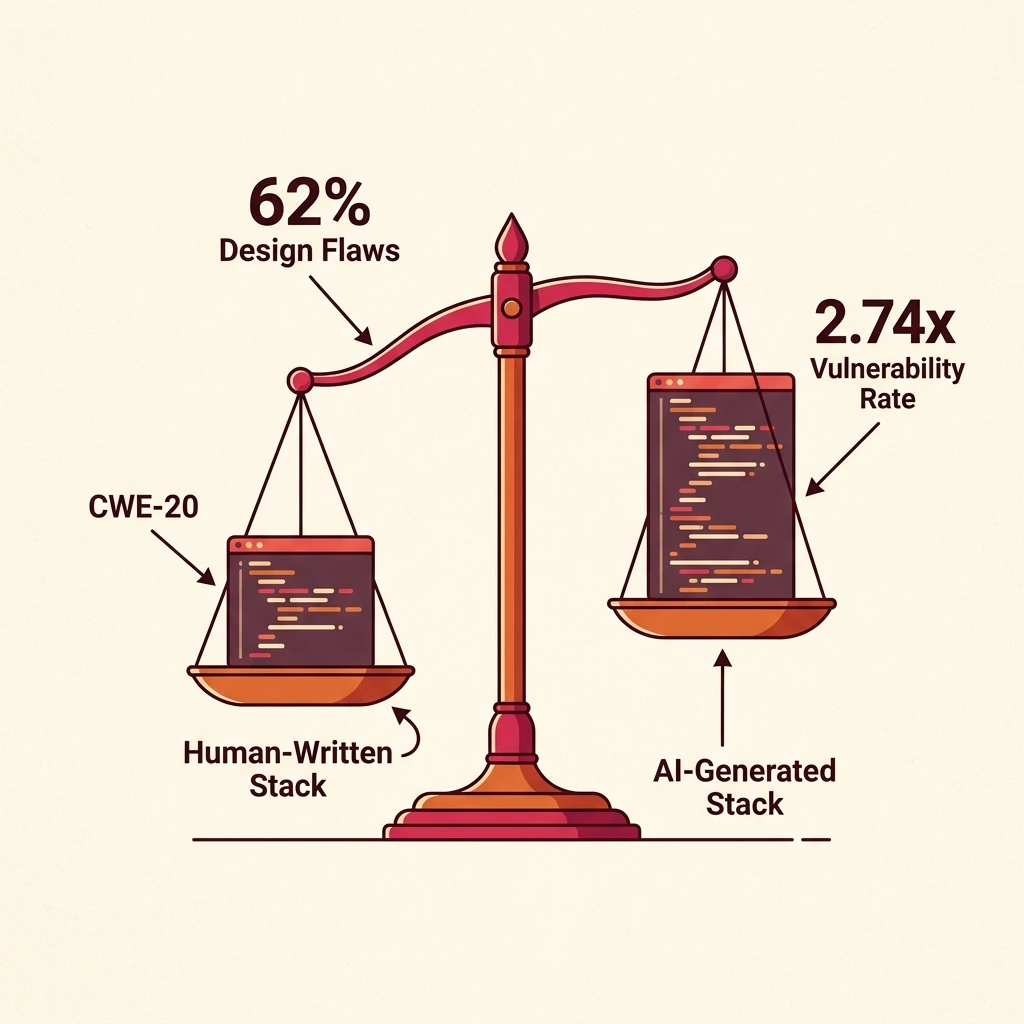
Endor Labs’ research quantified specific patterns in AI-generated output: missing input sanitization (CWE-20, or Common Weakness Enumeration category 20) emerged as the most common vulnerability class, and an estimated 62% of AI-generated solutions contained design flaws according to their analysis (Endor Labs). Endor Labs further reported that AI-generated code contained roughly 2.74 times more vulnerabilities than human-written code across their test corpus (Endor Labs). Neither figure is specific to Codex or Claude Code, but neither vendor has published independent, CWE-benchmarked results for the security quality of their generated output, leaving a gap that third-party auditing has yet to fill.
OWASP’s 2026 Top 10 for Agentic Applications lists both prompt injection and unsafe code generation among its top-tier risks for exactly this class of tool (OWASP). OpenAI’s response, treating its own output as untrusted via Codex Security, at least names the problem. Anthropic’s response relies on model-level alignment to reduce insecure patterns, plus sandbox constraints at runtime. Both approaches leave the output verification question partially open.
Summary: Security posture Compared
Which Tool for Which Threat
For teams operating in adversarial environments, open-source repositories with untrusted contributors, automated CI/CD pipelines processing external pull requests. Claude Code’s sandbox architecture provides a measurably smaller attack surface based on current evidence. Pairing any AI coding tool with a dedicated credential manager limits credential exposure if a sandbox boundary is ever breached.
For teams focused on output security, ensuring generated code does not introduce vulnerabilities into the codebase. Codex Security fills a gap that Claude Code does not yet address with a dedicated scanning tool. Running Codex Security as a secondary verification layer, regardless of which assistant generated the code, adds a defense-in-depth check that the security of these assistants field currently lacks as a standard practice. Developer launchers like Raycast that surface AI assistants within a unified workflow also reduce context-switching overhead, fewer tool boundaries means fewer opportunities for credentials or context to leak between disconnected environments. For practical implementation of injection defenses applicable to both tools, Decoded AI Tech’s guide to preventing prompt injection covers five production-tested techniques.
Anthropic’s sandbox-first model represents the more defensible Coding tool security architecture at present, a position a reasonable observer could contest, given that sandbox escapes are a matter of when, not if. OpenAI’s bet on post-generation scanning acknowledges a reality that sandboxing alone cannot address: the tool’s output is itself an attack surface, and no amount of runtime isolation changes what gets committed to the repository.
Every evaluation conducted so far has tested these tools against known injection patterns, adversarial strings planted in files, comments, and configurations. What remains untested at scale is what happens when injected content is not recognizably malicious: legitimate-looking code suggestions that introduce subtle, exploitable weaknesses months downstream. By late 2026, the comparison that matters between AI coding assistants will likely shift from “which one resists prompt injection better” to “which one’s training pipeline produces fewer latent vulnerabilities per thousand lines of generated code”, and neither vendor has published the data to answer that question yet.
Critics of this framing point out that the sandbox-versus-scanner dichotomy understates how rapidly both vendors iterate: OpenAI has shipped multiple Codex CLI updates since CVE-2025-61260, and a point-in-time architectural comparison risks encoding a temporary gap as a permanent verdict. The strongest counterargument is that developer velocity and environment integration, areas where Codex CLI has historically led, may matter more to real-world security outcomes than sandbox depth, because tools that friction-laden workflows get bypassed entirely, leaving no security layer at all. On this view, the most secure AI coding assistant is the one developers actually use within sanctioned pipelines, not the one with the most strong isolation on paper.
What to Read Next
- Preventing Prompt Injection: 5 Defenses That Work
- Langflow RCE Exploited Again , 20 Hours, No PoC, Creds Stolen
- 41.6M AI Scribe Consultations Hide an Unregulated Medical Device
References
-
OpenAI Codex CLI Command Injection Vulnerability (CVE-2025-61260) , Check Point Research analysis of the MCP server configuration flaw in Codex CLI.
-
Codex Bug Let Repo Files Execute Hidden Commands , BankInfoSecurity reporting on the command execution vector in Codex CLI’s file-processing pipeline.
-
Claude Code Sandboxing , Anthropic Engineering documentation on the two-layer sandbox architecture with filesystem and network isolation.
-
Claude Code Sandbox Documentation , Official documentation covering OS-level primitives (Seatbelt on macOS, bubblewrap on Linux).
-
Prompt Injection on Agentic Coding Assistants , January 2026 study classifying vulnerability levels across AI coding assistants with standardized injection payloads.
-
The Hidden Backdoor in Claude Coding Assistant , Lasso Security analysis of four indirect injection vector categories targeting Claude Code.
-
ToxicSkills: Malicious AI Agent Skills on ClawHub , Snyk audit of 3,984 AI agent skills finding 36.82% contained security flaws.
-
Cybersecurity Risks of AI-Generated Code , Georgetown CSET report identifying three risk categories in AI code generation.
-
Common Security Vulnerabilities in AI-Generated Code , Endor Labs research quantifying CWE patterns and vulnerability rates in AI-generated output.
-
From Assistant to Adversary: Exploiting Agentic AI Developer Tools , NVIDIA AI red team demonstration of indirect prompt injection attack chains via GitHub pull requests.
-
Codex Security Now in Research Preview , OpenAI announcement of post-generation vulnerability scanning for Codex output.
-
Anthropic Claude Code Sandbox , InfoQ industry analysis of the November 2025 sandbox release.
-
OWASP Top 10 for Agentic Applications 2026 , OWASP framework listing prompt injection and unsafe code generation as top-tier agentic AI risks.
-
OpenAI Codex CLI Contained Dangerous MCP Security Gap , Techzine analysis confirming the MCP configuration vulnerability in Codex CLI.