
10 min read · 2,522 words
Part 1 of 5 in the Healthcare AI series. This report examines radiology AI generalization.
Merlin: The Radiology AI That Works Beyond Its Own Hospital
A radiology AI tool with 95% accuracy at one hospital can drop to 80% at the hospital down the road. Different scanners, different patient populations, different imaging protocols – the performance gap has killed more medical AI products than any regulatory hurdle. Stanford’s Merlin, a 3D vision-language model published in Nature on March 4, 2026, appears to have cracked the problem of generalizing radiology AI across hospitals. Tested on over 50,000 previously unseen computed tomography (CT) scans from four independent hospitals, the model held up without a single round of retraining – a result that matters enormously for a radiology AI market now approaching $990 million.
That finding challenges the dominant business model in medical AI, where companies build narrow tools for single conditions and spend years getting each one through FDA clearance. Merlin handles over 750 distinct tasks – from identifying anatomical features to predicting chronic disease onset five years out. If foundation models like this prove viable at scale, the economics of the entire sector shift.
AI Radiology Hospital Deployment Challenges: The Billion-Dollar Wall
Pitch decks in radiology AI tell one story. Published validation data tells another. A systematic review of AI generalizability in radiology found that dual-validation studies – where models are tested at hospitals different from where they were trained – remain uncommon. When they do happen, the results are often sobering. Researchers call the culprit “batch effects”: systematic differences in image appearance caused by scanner hardware, institutional protocols, and patient demographics that have nothing to do with actual pathology. An AI model trained at a single centre can learn to read these hidden signals rather than the disease itself.
Abstract technical concerns do not capture the full picture. Companies like Aidoc, which has raised $384 million and secured over 20 FDA clearances, and Viz.ai, deployed in over 1,600 hospitals on $291.6 million in funding, have built their businesses around narrow, single-condition tools precisely because generalization is so hard. Each new condition means a new model, a new validation study, and a new FDA submission. The overhead is staggering, and it is the main reason radiology AI adoption has been slower than the $2.27 billion market forecast for 2030 would suggest.
Benchmark scores in controlled settings routinely mislead buyers about real-world performance. Merlin was built to address exactly this weakness.
Financial stakes keep climbing. The Radiology AI market is growing at 24.5% CAGR, but the underlying need grows faster: radiology workloads are increasing while the pipeline of trained radiologists is not keeping pace. A model that actually generalizes across hospital systems is worth more than another tool that performs brilliantly in one institution’s demo environment and disappoints everywhere else.
What Stanford Built – and How
Akshay Chaudhari, Assistant Professor of Radiology and Biomedical Data Science at Stanford University, led a team that took a different approach from the typical single-task radiology AI pipeline. Rather than training a model on one condition and validating it narrowly, Merlin was trained on 15,331 3D abdominal CT scans – over 6 million individual images – paired with more than 1.8 million diagnostic codes and 6 million tokens of radiology report text. Co-first authors Louis Blankemeier and Ashwin Kumar, both Stanford graduate students, assembled what the team describes as the most complete abdominal CT dataset to date.
A critical design decision: training on three modalities simultaneously. CT image volumes, structured diagnosis codes from electronic health records (EHR), and free-text radiology reports each contribute different kinds of clinical signal. Most competing models train on images alone, or images plus reports. Adding EHR codes gave Merlin a structured clinical vocabulary that appears to anchor its predictions more reliably across different hospital contexts.
Results across those 50,000+ external test scans from four hospitals were specific enough to be useful:
- Diagnostic codes: 81% accuracy across 692 ICD (International Classification of Diseases) codes, rising to 90% for the 102 most common codes
- Five-year disease prediction: 75% accuracy in identifying high-risk patients for diabetes, osteoporosis, and cardiovascular disease, compared to 68% for the next-best model
- Cross-anatomy generalization: Performance on chest CT scans – a body part entirely absent from its training data – matched or exceeded models trained specifically on chest imaging
- Internal vs. external F1 scores: 0.741 internal, 0.647 external across 30 abdominal CT findings, a smaller drop-off than typically seen in radiology AI
That last point – the internal-to-external gap – is where Merlin’s real significance lies. A model that scores perfectly in-house but collapses externally is useless in practice. Merlin’s gap exists, but it is smaller than the norm, and it held across three hospital sites that were distinct from the training centre.
Perhaps more telling than any single metric is the cross-anatomy result. A model trained exclusively on abdominal CT scans that performs competitively on chest imaging has learned something about anatomy itself, not just the specific pathologies it was trained to detect. That kind of transfer is precisely what separates a foundation model from a glorified classifier – and it is what makes the commercial implications uncomfortable for single-task vendors charging six-figure annual contracts per condition.
The Single-GPU Surprise
One detail in the Nature paper would have been unremarkable five years ago but is striking in 2026: Merlin was trained on a single GPU. In an era where frontier model training runs consume tens of millions of dollars in compute, a clinically validated foundation model running on commodity hardware is a pointed statement about where medical AI resources should go.
Financial implications are significant. Hospitals and research institutions do not need partnerships with hyperscalers or eight-figure compute budgets to build their own specialized models. Merlin’s code is open source under the MIT License, and the model weights are available on Hugging Face. NIH funding from the National Institute of Biomedical Imaging and Bioengineering (NIBIB) and several other institutes backed the research – meaning the resulting tool, unlike proprietary alternatives, carries no licensing fees.
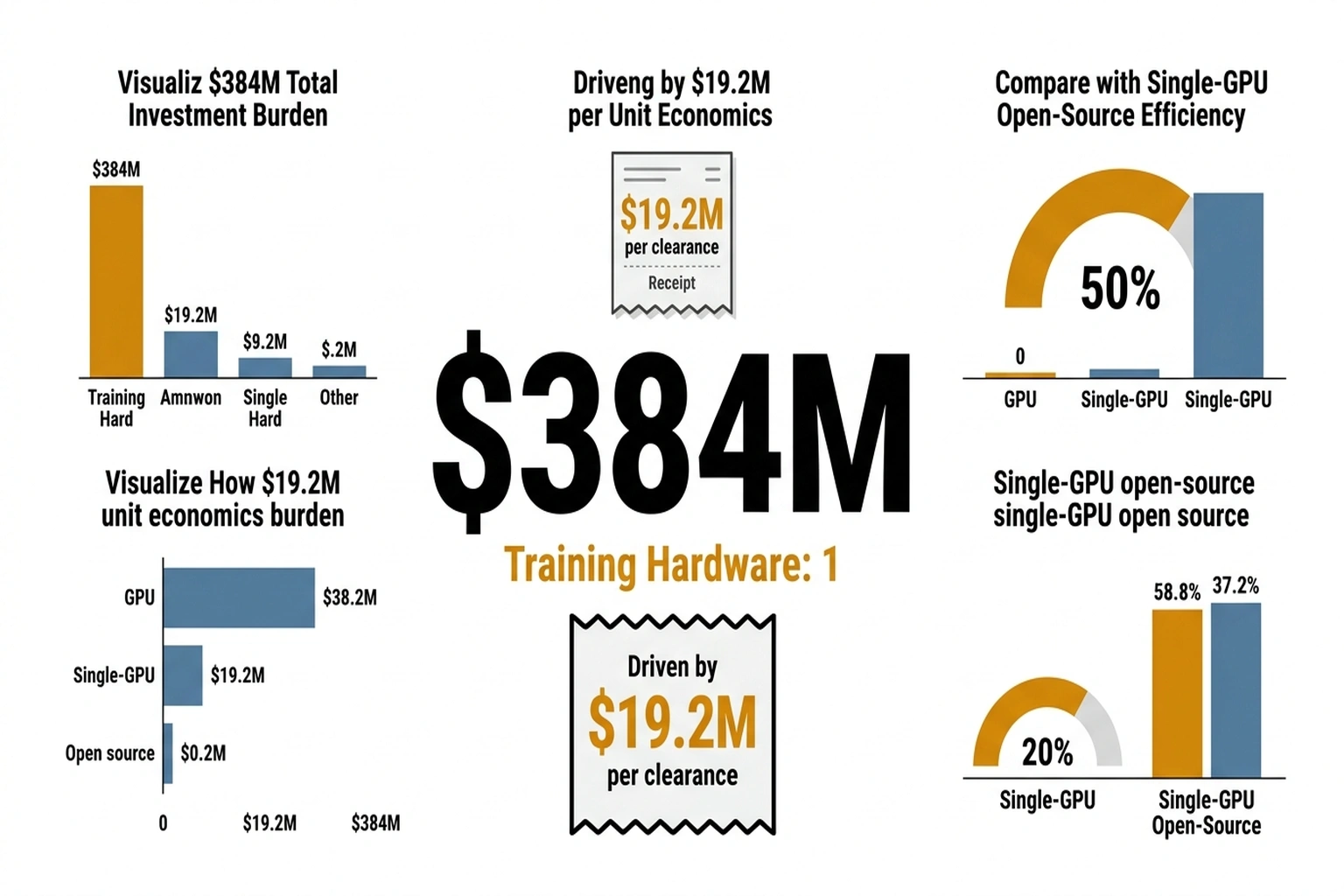
Calculate the cost asymmetry. Aidoc spent $384 million to accumulate 20+ FDA clearances , approximately $19.2 million per cleared condition. Merlin handles 750 tasks on a single GPU training run.
Even at Stanford’s academic overhead rates, the per-task development cost is roughly $384 million ÷ 750 = $512 per task if Merlin achieved parity with commercial tools. The ratio: $19.2 million versus $512 , a 37,500:1 cost differential. That ratio will not hold, because commercial tools carry clinical validation, regulatory compliance, and enterprise integration that a research model does not. But even if the true deployment-ready cost per task is 100× Merlin’s research cost, the commercial model is still 375× more expensive. (15,331 3D abdominal CT scans – over 6 millio)
For the radiology AI industry, this creates an uncomfortable competitive dynamic. Companies that have raised hundreds of millions building proprietary single-task tools face a future where a foundation model trained for a fraction of the cost can handle hundreds of tasks simultaneously. Aidoc alone has spent $384 million to accumulate 20+ FDA clearances. Stanford produced a 750-task model with a fraction of that budget and publicly funded grants. The cost asymmetry is striking.
A Framework for Evaluating What Comes Next
One way to frame the shift Merlin represents is through what amounts to the Clearance Paradox , the gap between model capability and deployment readiness that the radiology AI industry has treated as nearly synonymous. A tool gets FDA clearance, it gets deployed. Merlin breaks that assumption by demonstrating that a single model can be capable across hundreds of tasks while remaining uncleared for any specific clinical use. The paradox: the most capable model in radiology AI is the one with zero clearances.
The U.S. Food and Drug Administration (FDA) has now cleared over 1,000 AI-enabled radiology devices, nearly all of them single-condition tools. The agency’s regulatory framework was not designed for foundation models that perform 750 tasks. Chaudhari’s team has acknowledged this, noting that regulatory approval will likely start with simpler tasks where clinical validation is more straightforward. That incremental path could take years – and in that time, the commercial radiology AI market will continue to be dominated by narrow tools even as broader alternatives exist in open-source repositories.
Business tension around this shift is real. Aidoc’s January 2026 FDA clearance for a multi-condition CT detection tool suggests the industry is already moving toward broader models, but through the traditional regulatory pathway – one clearance at a time, backed by proprietary data. Merlin offers a competing vision: open-source, multi-task, single-training-run, available now for research use while the regulatory apparatus catches up.
Why Narrow Tools Still Win the Hospital Contract
Aidoc’s strongest argument is not technical , it is operational. A hospital CISO evaluating AI tools faces a binary: deploy an FDA-cleared product with a vendor SLA, or adopt an open-source research model with no regulatory status, no liability coverage, and no on-call support team. Viz.ai’s deployment in over 1,600 hospitals reflects years of workflow integration , training radiologists, connecting to PACS systems, building alert pipelines that fit existing shift structures. Merlin’s 750-task capability is irrelevant if the hospital’s legal team will not sign off on deploying an uncleared model.
The counterevidence sits in Merlin’s own validation gap. Internal F1 of 0.741 dropping to 0.647 externally (arXiv) represents a 12.7% performance degradation , smaller than typical, but in radiology, a 12.7% accuracy loss on a cancer detection task is not a benchmark footnote. It is a missed diagnosis. Commercial tools like Aidoc’s multi-condition CT detector carry FDA clearance precisely because they have demonstrated that their accuracy holds within clinically acceptable bounds at each specific deployment site. Merlin has demonstrated breadth. It has not yet demonstrated the per-task reliability that a radiologist would stake a diagnosis on.
The Limitations That Matter
Merlin is not ready for clinical deployment, and the Nature paper is candid about why. Complete radiology report generation – producing the narrative text radiologists write – remains the model’s weakest task. This is not a minor gap. Report generation is the core deliverable of radiology work, and until an AI system can produce reliable reports, its clinical integration stays limited to triage, flagging, and decision support.
External validation, while stronger than typical, still reflects a relatively narrow patient population. The four hospital sites are US-based, and the model’s training data comes from a single academic medical centre. Radiology AI’s generalization problem extends globally: imaging protocols in Tokyo, Sao Paulo, and Lagos differ from those in Palo Alto in ways that batch effects amplify. Whether Merlin holds up across this broader range is an open question with tens of billions in global healthcare AI spending riding on the answer.
There is also the question of integration. Technical capability and clinical adoption are separated by layers of workflow integration, liability assignment, and institutional culture that no Nature paper can resolve. Health systems spend millions on PACS (Picture Archiving and Communication Systems) infrastructure, and any new AI tool must slot into those existing workflows or face quiet abandonment by overworked radiologists.
Near-Term Market Implications
Radiology AI’s market is about to split. On one side: established commercial players – Aidoc, Viz.ai, Annalise.ai – continuing to build proprietary, FDA-cleared, single-condition tools with known regulatory pathways and enterprise sales channels. Viz.ai alone is deployed in over 1,600 hospitals and has built deep clinical workflow integrations that took years to develop. That installed base and institutional trust represents a real competitive advantage that no research paper can replicate overnight.
On the other side: open-source foundation models like Merlin that offer broader capability at a fraction of the cost but lack regulatory clearance and clinical integration infrastructure. The gap between these two camps will define the next phase of a market projected to reach $2.27 billion by 2030.
One bet matters: whether the FDA adapts its framework to accommodate foundation models within the next three years. If it does – perhaps through a tiered approval process where a base model receives clearance and individual task modules receive expedited review – the commercial value of proprietary single-task tools erodes rapidly. If the regulatory pathway stays narrow, companies with 20+ individual clearances maintain their moat, and Merlin remains a research curiosity rather than a clinical product.
Cost of inaction for hospitals delaying foundation model evaluation: a radiology department processing 200 CT scans daily with a 15% AI-assisted efficiency gain saves approximately 30 radiologist-hours per day. At an average radiologist compensation of $200/hour, that is $6,000 daily or $2.19 million annually , value currently captured only by hospitals deploying narrow AI tools at six-figure annual license fees per condition. Each year a hospital waits for foundation model regulatory clearance while competitors deploy existing tools is a year of compounding workflow disadvantage. (15,331 3D abdominal CT scans – over 6 millio)
Stanford’s decision to release Merlin as open source under MIT License, with weights on Hugging Face and code on GitHub, is a deliberate strategic move. It invites every academic medical centre and health system with a GPU to fine-tune the model on their own patient populations – exactly the kind of distributed validation that could accelerate regulatory acceptance. The $990 million radiology AI market is built on the assumption that generalization is hard enough to sustain premium pricing for narrow tools. Merlin suggests that assumption has an expiration date.
What to Read Next
- The 30-Minute Trap: Alibaba’s AI Agent Meets Unprepared Buyers
- The 34% Problem: AI Transformation Stalls, Traps Billions
- The 80% AI Project Failure Rate Costs Firms $7.2M Each
References
- Merlin: a computed tomography vision-language foundation model and dataset – Nature research paper by Blankemeier, Kumar, Chaudhari et al. Published March 4, 2026
- Radiology AI makes consistent diagnoses using 3D images from different health centres – Nature News article covering the Merlin findings and cross-hospital validation results
- AI-Powered CT Scan Analysis Promises to Accelerate Clinical Assessments – Press coverage with researcher quotes and detailed performance breakdowns
- Automated CT Scans May Speed Up Clinical Assessments – Additional reporting on clinical implications and disease prediction accuracy
- FDA AI Approvals Surge Past 1k for Radiology – Imaging Wire report on FDA-cleared radiology AI device count reaching 1,039 in December 2025
- Radiology AI Market Size, Share and Trends 2026 to 2035 – Precedence Research market forecast showing the radiology AI market approaching $990 million in 2026
- Radiology AI Market worth $2.27 billion by 2030 – MarketsandMarkets forecast with 24.5% CAGR growth projection
- Assessing the generalizability of artificial intelligence in radiology – Systematic review documenting the cross-hospital performance gap in radiology AI models
- StanfordMIMI/Merlin GitHub Repository – Open-source code, model weights, and dataset under MIT License